自定义音频流应用(SSE)¶
本文概述了使用 ADK Streaming 和 FastAPI 构建的自定义异步 web 应用的服务器和客户端代码,通过服务器发送事件(SSE)实现实时、双向音频和文本通信。关键特性包括:
服务器端(Python/FastAPI):
- FastAPI + ADK 集成
- 用于实时流传输的服务器发送事件
- 具有独立用户上下文的会话管理
- 支持文本和音频通信模式
- Google 搜索工具集成用于基础响应
客户端(JavaScript/Web Audio API):
- 通过 SSE 和 HTTP POST 实现实时双向通信
- 使用 AudioWorklet 处理器进行专业音频处理
- 文本和音频模式之间的无缝切换
- 自动重连和错误处理
- 音频数据传输的 Base64 编码
还有一个 WebSocket 版本的示例可用。
1. 安装 ADK¶
创建并激活虚拟环境(推荐):
# 创建
python -m venv .venv
# 激活(每个新终端)
# macOS/Linux: source .venv/bin/activate
# Windows CMD: .venv\Scripts\activate.bat
# Windows PowerShell: .venv\Scripts\Activate.ps1
安装 ADK:
使用以下命令设置 SSL_CERT_FILE 变量。
下载示例代码:
git clone --no-checkout https://github.com/google/adk-docs.git
cd adk-docs
git sparse-checkout init --cone
git sparse-checkout set examples/python/snippets/streaming/adk-streaming
git checkout main
cd examples/python/snippets/streaming/adk-streaming/app
此示例代码包含以下文件和文件夹:
adk-streaming/
└── app/ # Web 应用文件夹
├── .env # Gemini API 密钥 / Google Cloud 项目 ID
├── main.py # FastAPI Web 应用
├── static/ # 静态内容文件夹
| ├── js # JavaScript 文件文件夹(包含 app.js)
| └── index.html # Web 客户端页面
└── google_search_agent/ # 智能体文件夹
├── __init__.py # Python 包
└── agent.py # 智能体定义
2. 设置平台¶
要运行示例应用,请从 Google AI Studio 或 Google Cloud Vertex AI 中选择一个平台:
- 从 Google AI Studio 获取 API 密钥。
-
打开位于 (
app/) 内的.env文件,并复制粘贴以下代码。 -
将
PASTE_YOUR_ACTUAL_API_KEY_HERE替换为你的实际API KEY。
- 你需要一个现有的 Google Cloud 账户和一个项目。
*设置一个
Google Cloud 项目
- 设置
gcloud CLI
*通过在终端运行
gcloud auth login向 Google Cloud 进行身份验证。 - 启用 Vertex AI API。
- 设置
gcloud CLI
*通过在终端运行
-
打开位于 (
app/) 内的.env文件。复制粘贴以下代码并更新项目 ID 和位置。
3. 与你的流应用互动¶
- 导航到正确的目录:
要有效运行你的智能体,请确保你在 app 文件夹 (adk-streaming/app) 中
- 启动 Fast API:运行以下命令启动 CLI 界面
- 以文本模式访问应用: 一旦应用启动,终端将显示一个本地 URL(例如 http://localhost:8000)。点击此链接在浏览器中打开 UI。
现在你应该看到如下所示的 UI:
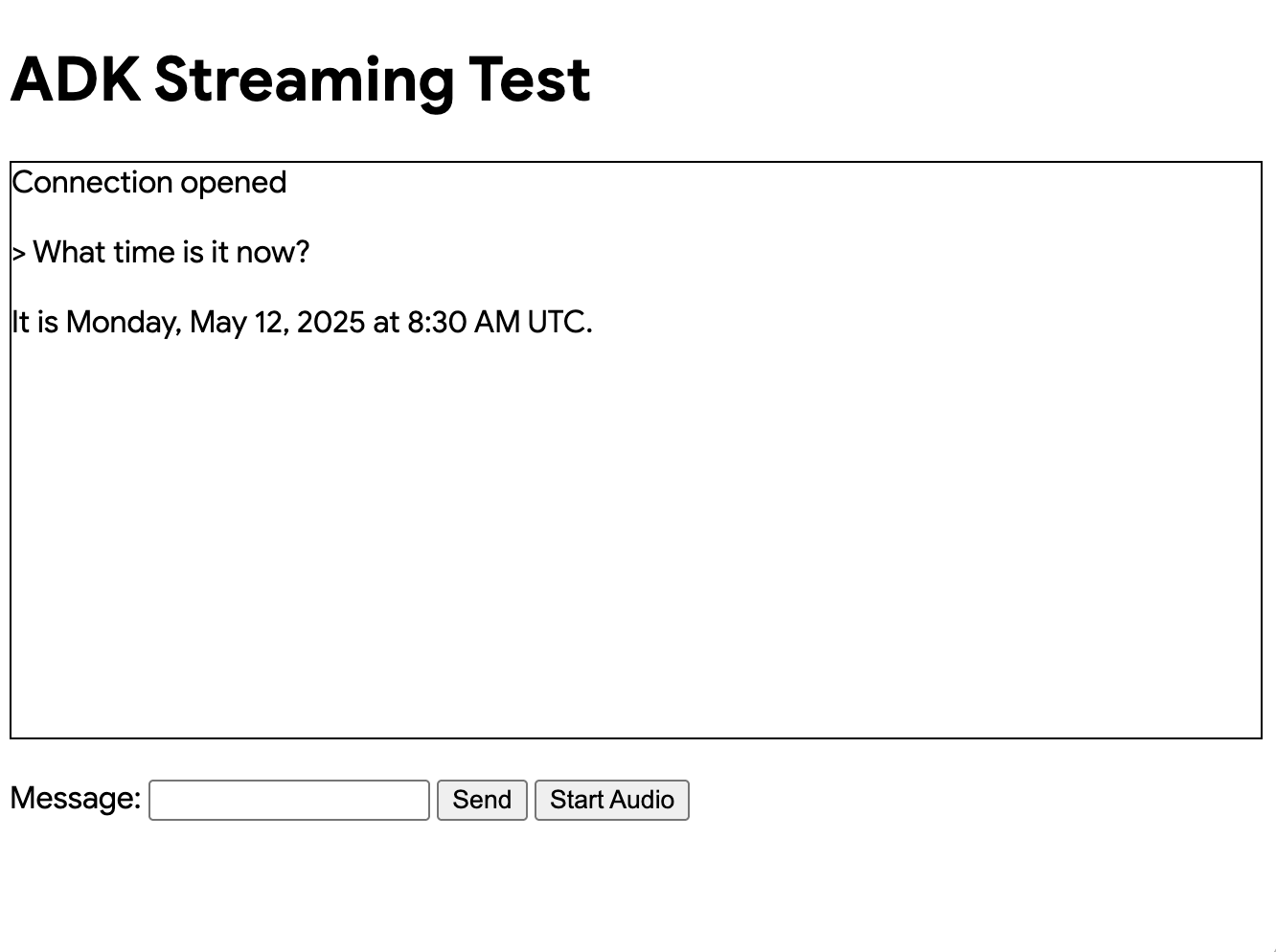
尝试提问 What time is it now?。智能体将使用 Google 搜索回应你的查询。你会注意到 UI 以流式文本显示智能体的回应。即使在智能体仍在回应时,你也可以随时向智能体发送消息。这展示了 ADK Streaming 的双向通信能力。
- 以音频模式访问应用: 现在点击
Start Audio按钮。应用将以音频模式重新连接服务器,首次使用时 UI 将显示以下对话框:
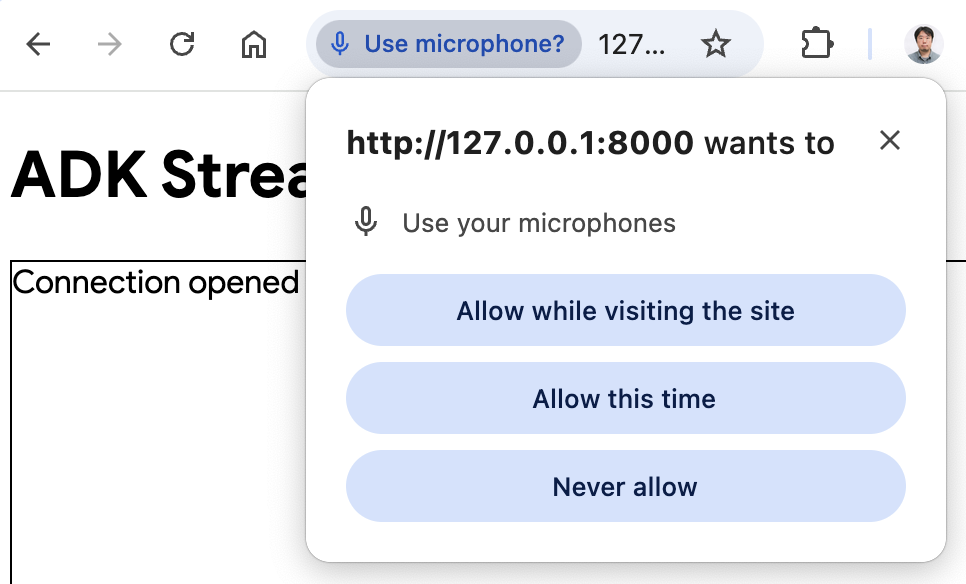
点击 Allow while visiting the site,然后你将看到麦克风图标显示在浏览器顶部:
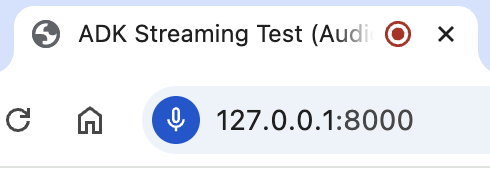
现在你可以用语音与智能体交谈。用语音提问类似 What time is it now? 的问题,你也会听到智能体用语音回应。由于 ADK 的 Streaming 支持 多种语言,它也可以用支持的语言回应问题。
- 查看控制台日志
如果你使用 Chrome 浏览器,右键点击并选择 Inspect 打开 DevTools。在 Console 中,你可以看到传入和传出的音频数据,例如 [CLIENT TO AGENT] 和 [AGENT TO CLIENT],表示浏览器和服务器之间流入和流出的音频数据。
同时,在应用服务器控制台中,你应该会看到类似这样的内容:
Client #90766266 connected via SSE, audio mode: false
INFO: 127.0.0.1:52692 - "GET /events/90766266?is_audio=false HTTP/1.1" 200 OK
[CLIENT TO AGENT]: hi
INFO: 127.0.0.1:52696 - "POST /send/90766266 HTTP/1.1" 200 OK
[AGENT TO CLIENT]: text/plain: {'mime_type': 'text/plain', 'data': 'Hi'}
[AGENT TO CLIENT]: text/plain: {'mime_type': 'text/plain', 'data': ' there! How can I help you today?\n'}
[AGENT TO CLIENT]: {'turn_complete': True, 'interrupted': None}
如果你开发自己的流应用,这些控制台日志非常重要。在许多情况下,浏览器和服务器之间的通信失败是流应用 bug 的主要原因。
-
故障排除提示
-
当浏览器无法通过 SSH 代理连接到服务器时: 各种云服务中使用的 SSH 代理可能无法与 SSE 兼容。请尝试不使用 SSH 代理,比如使用本地笔记本电脑,或者尝试 WebSocket 版本。
-
当
gemini-2.0-flash-exp模型无法工作时: 如果在应用程序服务器控制台上看到与gemini-2.0-flash-exp模型可用性相关的任何错误,请尝试在app/google_search_agent/agent.py文件的第 6 行将其替换为gemini-2.0-flash-live-001。
4. 智能体定义¶
google_search_agent 文件夹中的智能体定义代码 agent.py 是编写智能体逻辑的地方:
from google.adk.agents import Agent
from google.adk.tools import google_search # 导入工具
root_agent = Agent(
name="google_search_agent",
model="gemini-2.0-flash-exp", # 如果此模型不工作,请尝试下面的
#model="gemini-2.0-flash-live-001",
description="使用 Google 搜索回答问题的智能体。",
instruction="使用 Google 搜索工具回答问题。",
tools=[google_search],
)
注意你如何轻松集成 Google 搜索基础 功能。Agent 类和 google_search 工具处理与 LLM 的复杂交互以及与搜索 API 的基础,让你专注于智能体的 目的 和 行为。

服务器和客户端架构支持 web 客户端和 AI 智能体之间的实时、双向通信,具有适当的会话隔离和资源管理。
5. 服务器端代码概述¶
FastAPI 服务器在 web 客户端和 AI 智能体之间提供实时通信。
双向通信概述¶
客户端到智能体的流程¶
- 连接建立 - 客户端打开到
/events/{user_id}的 SSE 连接,触发会话创建并将请求队列存储在active_sessions中 - 消息传输 - 客户端向
/send/{user_id}发送 POST 请求,包含mime_type和data的 JSON 负载 - 队列处理 - 服务器检索会话的
live_request_queue并通过send_content()或send_realtime()将消息转发给智能体
智能体到客户端的流程¶
- 事件生成 - 智能体处理请求并通过
live_events异步生成器生成事件 - 流处理 -
agent_to_client_sse()过滤事件并将其格式化为与 SSE 兼容的 JSON - 实时传递 - 事件通过持久的 HTTP 连接和适当的 SSE 头部流式传输到客户端
会话管理¶
- 每用户隔离 - 每个用户获得存储在
active_sessions字典中的唯一会话 - 生命周期管理 - 会话在断开连接时自动清理,并进行适当的资源清理
- 并发支持 - 多个用户可以同时拥有活跃会话
错误处理¶
- 会话验证 - POST 请求在处理前验证会话存在
- 流弹性 - SSE 流处理异常并自动执行清理
- 连接恢复 - 客户端可以通过重新建立 SSE 连接来重新连接
会话恢复¶
- 实时会话恢复 - 实现对中断的实时对话的透明重连
- 句柄缓存 - 系统自动缓存会话句柄以便恢复
- 可靠性增强 - 提高流传输期间对网络不稳定的弹性
智能体会话管理¶
start_agent_session() 函数创建独立的 AI 智能体会话:
async def start_agent_session(user_id, is_audio=False):
"""启动智能体会话"""
# 创建 Runner
runner = InMemoryRunner(
app_name=APP_NAME,
agent=root_agent,
)
# 创建会话
session = await runner.session_service.create_session(
app_name=APP_NAME,
user_id=user_id, # 替换为实际用户 ID
)
# 设置响应模态
modality = "AUDIO" if is_audio else "TEXT"
run_config = RunConfig(response_modalities=[modality])
# 可选:启用会话恢复以提高可靠性
# run_config = RunConfig(
# response_modalities=[modality],
# session_resumption=types.SessionResumptionConfig()
# )
# 为此会话创建 LiveRequestQueue
live_request_queue = LiveRequestQueue()
# 启动智能体会话
live_events = runner.run_live(
session=session,
live_request_queue=live_request_queue,
run_config=run_config,
)
return live_events, live_request_queue
-
InMemoryRunner 设置 - 创建一个在内存中管理智能体生命周期的运行器实例,使用应用名称"ADK Streaming example"和 Google 搜索智能体。
-
会话创建 - 使用
runner.session_service.create_session()为每个用户 ID 建立唯一会话,支持多个并发用户。 -
响应模态配置 - 根据
is_audio参数设置RunConfig,可以是"AUDIO"或"TEXT"模态,决定输出格式。 -
LiveRequestQueue - 创建一个双向通信通道,对传入请求进行排队,并在客户端和智能体之间启用实时消息传递。
-
实时事件流 -
runner.run_live()返回一个异步生成器,产生来自智能体的实时事件,包括部分响应、轮次完成和中断。
服务器发送事件(SSE)流¶
agent_to_client_sse() 函数处理从智能体到客户端的实时流:
async def agent_to_client_sse(live_events):
"""通过 SSE 进行智能体到客户端的通信"""
async for event in live_events:
# 如果轮次完成或中断,发送它
if event.turn_complete or event.interrupted:
message = {
"turn_complete": event.turn_complete,
"interrupted": event.interrupted,
}
yield f"data: {json.dumps(message)}\n\n"
print(f"[AGENT TO CLIENT]: {message}")
continue
# 读取内容和其第一个部分
part: Part = (
event.content and event.content.parts and event.content.parts[0]
)
if not part:
continue
# 如果是音频,发送 Base64 编码的音频数据
is_audio = part.inline_data and part.inline_data.mime_type.startswith("audio/pcm")
if is_audio:
audio_data = part.inline_data and part.inline_data.data
if audio_data:
message = {
"mime_type": "audio/pcm",
"data": base64.b64encode(audio_data).decode("ascii")
}
yield f"data: {json.dumps(message)}\n\n"
print(f"[AGENT TO CLIENT]: audio/pcm: {len(audio_data)} bytes.")
continue
# 如果是文本且是部分文本,发送它
if part.text and event.partial:
message = {
"mime_type": "text/plain",
"data": part.text
}
yield f"data: {json.dumps(message)}\n\n"
print(f"[AGENT TO CLIENT]: text/plain: {message}")
-
事件处理循环 - 迭代
live_events异步生成器,处理从智能体到达的每个事件。 -
轮次管理 - 检测对话轮次完成或中断事件,并发送带有
turn_complete和interrupted标志的 JSON 消息以表示对话状态变化。 -
内容部分提取 - 从事件内容中提取第一个
Part,其中包含文本或音频数据。 -
音频流 - 通过以下方式处理 PCM 音频数据:
- 检测
inline_data中的audio/pcmMIME 类型 - 对原始音频字节进行 Base64 编码以用于 JSON 传输
-
使用
mime_type和data字段发送 -
文本流 - 通过发送增量文本更新来处理部分文本响应,支持实时打字效果。
-
SSE 格式 - 所有数据都格式化为
data: {json}\n\n,遵循 SSE 规范以与浏览器 EventSource API 兼容。
HTTP 端点和路由¶
根端点¶
GET / - 使用 FastAPI 的 FileResponse 将 static/index.html 作为主应用界面提供。
SSE 事件端点¶
@app.get("/events/{user_id}")
async def sse_endpoint(user_id: int, is_audio: str = "false"):
"""智能体到客户端通信的 SSE 端点"""
# 启动智能体会话
user_id_str = str(user_id)
live_events, live_request_queue = await start_agent_session(user_id_str, is_audio == "true")
# 为此用户存储请求队列
active_sessions[user_id_str] = live_request_queue
print(f"Client #{user_id} connected via SSE, audio mode: {is_audio}")
def cleanup():
live_request_queue.close()
if user_id_str in active_sessions:
del active_sessions[user_id_str]
print(f"Client #{user_id} disconnected from SSE")
async def event_generator():
try:
async for data in agent_to_client_sse(live_events):
yield data
except Exception as e:
print(f"Error in SSE stream: {e}")
finally:
cleanup()
return StreamingResponse(
event_generator(),
media_type="text/event-stream",
headers={
"Cache-Control": "no-cache",
"Connection": "keep-alive",
"Access-Control-Allow-Origin": "*",
"Access-Control-Allow-Headers": "Cache-Control"
}
)
GET /events/{user_id} - 建立持久的 SSE 连接:
-
参数 - 接受
user_id(int)和可选的is_audio查询参数(默认为"false") -
会话初始化 - 调用
start_agent_session()并使用user_id作为键将live_request_queue存储在active_sessions字典中 -
StreamingResponse - 返回具有以下内容的
StreamingResponse: - 包装
agent_to_client_sse()的event_generator()异步函数 - MIME 类型:
text/event-stream - 用于跨源访问的 CORS 头部
-
防止缓存的缓存控制头部
-
清理逻辑 - 通过关闭请求队列并从活跃会话中移除来处理连接终止,并对流中断进行错误处理。
会话恢复配置¶
ADK 支持实时会话恢复以提高流对话期间的可靠性。此功能在网络问题导致实时连接中断时实现自动重连。
启用会话恢复¶
要启用会话恢复,你需要:
- 导入所需的类型:
- 在 RunConfig 中配置会话恢复:
run_config = RunConfig(
response_modalities=[modality],
session_resumption=types.SessionResumptionConfig()
)
会话恢复功能¶
- 自动句柄缓存 - 系统在实时对话期间自动缓存会话恢复句柄
- 透明重连 - 当连接中断时,系统尝试使用缓存的句柄恢复
- 上下文保持 - 对话上下文和状态在重连过程中得到保持
- 网络弹性 - 在不稳定的网络条件下提供更好的用户体验
实现说明¶
- 会话恢复句柄由 ADK 框架内部管理
- 不需要额外的客户端代码更改
- 此功能对长时间运行的流对话特别有益
- 连接中断对用户体验的干扰更小
故障排除¶
如果你遇到会话恢复错误:
- 检查模型兼容性 - 确保你使用的是支持会话恢复的模型
- API 限制 - 某些会话恢复功能可能不在所有 API 版本中可用
- 移除会话恢复 - 如果问题持续存在,你可以通过从
RunConfig中移除session_resumption参数来禁用会话恢复
消息发送端点¶
@app.post("/send/{user_id}")
async def send_message_endpoint(user_id: int, request: Request):
"""客户端到智能体通信的 HTTP 端点"""
user_id_str = str(user_id)
# 获取此用户的实时请求队列
live_request_queue = active_sessions.get(user_id_str)
if not live_request_queue:
return {"error": "Session not found"}
# 解析消息
message = await request.json()
mime_type = message["mime_type"]
data = message["data"]
# 将消息发送给智能体
if mime_type == "text/plain":
content = Content(role="user", parts=[Part.from_text(text=data)])
live_request_queue.send_content(content=content)
print(f"[CLIENT TO AGENT]: {data}")
elif mime_type == "audio/pcm":
decoded_data = base64.b64decode(data)
live_request_queue.send_realtime(Blob(data=decoded_data, mime_type=mime_type))
print(f"[CLIENT TO AGENT]: audio/pcm: {len(decoded_data)} bytes")
else:
return {"error": f"Mime type not supported: {mime_type}"}
return {"status": "sent"}
POST /send/{user_id} - 接收客户端消息:
-
会话查找 - 从
active_sessions检索live_request_queue,如果会话不存在则返回错误 -
消息处理 - 解析带有
mime_type和data字段的 JSON: - 文本消息 - 使用
Part.from_text()创建Content并通过send_content()发送 -
音频消息 - Base64 解码 PCM 数据并通过
send_realtime()与Blob一起发送 -
错误处理 - 对不支持的 MIME 类型或缺失会话返回适当的错误响应。
6. 客户端代码概述¶
客户端由具有实时通信和音频功能的 web 界面组成:
HTML 界面(static/index.html)¶
<!doctype html>
<html>
<head>
<title>ADK Streaming Test (Audio)</title>
<script src="/static/js/app.js" type="module"></script>
</head>
<body>
<h1>ADK Streaming Test</h1>
<div
id="messages"
style="height: 300px; overflow-y: auto; border: 1px solid black"></div>
<br />
<form id="messageForm">
<label for="message">Message:</label>
<input type="text" id="message" name="message" />
<button type="submit" id="sendButton" disabled>Send</button>
<button type="button" id="startAudioButton">Start Audio</button>
</form>
</body>
</html>
简单的 web 界面包含:
- 消息显示 - 用于对话历史的可滚动 div
- 文本输入表单 - 用于文本消息的输入字段和发送按钮
- 音频控制 - 启用音频模式和麦克风访问的按钮
主应用逻辑(static/js/app.js)¶
会话管理(app.js)¶
const sessionId = Math.random().toString().substring(10);
const sse_url =
"http://" + window.location.host + "/events/" + sessionId;
const send_url =
"http://" + window.location.host + "/send/" + sessionId;
let is_audio = false;
- 随机会话 ID - 为每个浏览器实例生成唯一的会话 ID
- URL 构造 - 使用会话 ID 构建 SSE 和发送端点
- 音频模式标志 - 跟踪是否启用了音频模式
服务器发送事件连接(app.js)¶
connectSSE() 函数处理实时服务器通信:
// SSE 处理程序
function connectSSE() {
// 连接到 SSE 端点
eventSource = new EventSource(sse_url + "?is_audio=" + is_audio);
// 处理连接打开
eventSource.onopen = function () {
// 连接打开消息
console.log("SSE connection opened.");
document.getElementById("messages").textContent = "Connection opened";
// 启用发送按钮
document.getElementById("sendButton").disabled = false;
addSubmitHandler();
};
// 处理传入消息
eventSource.onmessage = function (event) {
...
};
// 处理连接关闭
eventSource.onerror = function (event) {
console.log("SSE connection error or closed.");
document.getElementById("sendButton").disabled = true;
document.getElementById("messages").textContent = "Connection closed";
eventSource.close();
setTimeout(function () {
console.log("Reconnecting...");
connectSSE();
}, 5000);
};
}
- EventSource 设置 - 使用音频模式参数创建 SSE 连接
- 连接处理程序:
- onopen - 连接时启用发送按钮和表单提交
- onmessage - 处理来自智能体的传入消息
- onerror - 处理断开连接,5 秒后自动重连
消息处理(app.js)¶
处理来自服务器的不同消息类型:
// 处理传入消息
eventSource.onmessage = function (event) {
// 解析传入消息
const message_from_server = JSON.parse(event.data);
console.log("[AGENT TO CLIENT] ", message_from_server);
// 检查轮次是否完成
// 如果轮次完成,添加新消息
if (
message_from_server.turn_complete &&
message_from_server.turn_complete == true
) {
currentMessageId = null;
return;
}
// 如果是音频,播放它
if (message_from_server.mime_type == "audio/pcm" && audioPlayerNode) {
audioPlayerNode.port.postMessage(base64ToArray(message_from_server.data));
}
// 如果是文本,打印它
if (message_from_server.mime_type == "text/plain") {
// 为新轮次添加新消息
if (currentMessageId == null) {
currentMessageId = Math.random().toString(36).substring(7);
const message = document.createElement("p");
message.id = currentMessageId;
// 将消息元素附加到 messagesDiv
messagesDiv.appendChild(message);
}
// 将消息文本添加到现有消息元素
const message = document.getElementById(currentMessageId);
message.textContent += message_from_server.data;
// 向下滚动到 messagesDiv 底部
messagesDiv.scrollTop = messagesDiv.scrollHeight;
}
- 轮次管理 - 检测
turn_complete以重置消息状态 - 音频播放 - 解码 Base64 PCM 数据并发送到音频工作节点
- 文本显示 - 创建新消息元素并附加部分文本更新以实现实时打字效果
消息发送(app.js)¶
sendMessage() 函数向服务器发送数据:
async function sendMessage(message) {
try {
const response = await fetch(send_url, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
body: JSON.stringify(message)
});
if (!response.ok) {
console.error('Failed to send message:', response.statusText);
}
} catch (error) {
console.error('Error sending message:', error);
}
}
- HTTP POST - 向
/send/{session_id}端点发送 JSON 负载 - 错误处理 - 记录失败的请求和网络错误
- 消息格式 - 标准化的
{mime_type, data}结构
音频播放器(static/js/audio-player.js)¶
startAudioPlayerWorklet() 函数:
- AudioContext 设置 - 创建 24kHz 采样率的上下文用于播放
- 工作节点加载 - 加载 PCM 播放器处理器用于音频处理
- 音频流水线 - 将工作节点连接到音频目标(扬声器)
音频录制器(static/js/audio-recorder.js)¶
startAudioRecorderWorklet() 函数:
- AudioContext 设置 - 创建 16kHz 采样率的上下文用于录制
- 麦克风访问 - 请求用户媒体权限用于音频输入
- 音频处理 - 将麦克风连接到录制器工作节点
- 数据转换 - 将 Float32 采样转换为 16 位 PCM 格式
音频工作节点处理器¶
PCM 播放器处理器(static/js/pcm-player-processor.js)¶
PCMPlayerProcessor 类处理音频播放:
- 环形缓冲区 - 用于 180 秒 24kHz 音频的循环缓冲区
- 数据摄取 - 将 Int16 转换为 Float32 并存储在缓冲区中
- 播放循环 - 持续从缓冲区读取到输出通道
- 溢出处理 - 当缓冲区满时覆盖最旧的采样
PCM 录制器处理器(static/js/pcm-recorder-processor.js)¶
PCMProcessor 类捕获麦克风输入:
- 音频输入 - 处理传入的音频帧
- 数据传输 - 复制 Float32 采样并通过消息端口发布到主线程
模式切换:¶
- 音频激活 - "Start Audio"按钮启用麦克风并使用音频标志重新连接 SSE
- 无缝转换 - 关闭现有连接并建立新的启用音频的会话
客户端架构使用现代 web API 实现专业级音频处理,支持文本和音频模态的无缝实时通信。
总结¶
此应用展示了一个完整的实时 AI 智能体系统,具有以下关键特性:
架构亮点:
- 实时:具有部分文本更新和连续音频的流响应
- 健壮:全面的错误处理和自动恢复机制
- 现代:使用最新的 web 标准(AudioWorklet、SSE、ES6 模块)
该系统为构建需要实时交互、web 搜索功能和多媒体通信的复杂 AI 应用提供了基础。
生产环境的后续步骤¶
要在生产环境中部署此系统,请考虑实施以下改进:
安全性¶
- 身份验证:用适当的用户身份验证替换随机会话 ID
- API 密钥安全:使用环境变量或密钥管理服务
- HTTPS:对所有通信强制使用 TLS 加密
- 速率限制:防止滥用并控制 API 成本
可扩展性¶
- 持久存储:用持久会话替换内存中的会话
- 负载均衡:支持具有共享会话状态的多个服务器实例
- 音频优化:实施压缩以减少带宽使用
监控¶
- 错误跟踪:监控系统故障并发出警报
- API 成本监控:跟踪 Google 搜索和 Gemini 使用情况以防止预算超支
- 性能指标:监控响应时间和音频延迟
基础设施¶
- 容器化:使用 Docker 打包以与 Cloud Run 或智能体引擎进行一致部署
- 健康检查:实施端点监控以进行正常运行时间跟踪