自定义音频流应用(WebSocket){#custom-streaming-websocket}¶
本文概述了使用 ADK Streaming 和 FastAPI 构建的自定义异步 web 应用的服务器和客户端代码,通过 WebSocket 实现实时、双向音频和文本通信。
注意: 本指南假设你有 JavaScript 和 Python asyncio 编程经验。
支持语音/视频流的模型¶
要在 ADK 中使用语音/视频流,你需要使用支持 Live API 的 Gemini 模型。你可以在文档中找到支持 Gemini Live API 的 模型 ID:
1. 安装 ADK¶
创建并激活虚拟环境(推荐):
# 创建
python -m venv .venv
# 激活(每个新终端)
# macOS/Linux: source .venv/bin/activate
# Windows CMD: .venv\Scripts\activate.bat
# Windows PowerShell: .venv\Scripts\Activate.ps1
安装 ADK:
使用以下命令设置 SSL_CERT_FILE 变量。
下载示例代码:
git clone --no-checkout https://github.com/google/adk-docs.git
cd adk-docs
git sparse-checkout init --cone
git sparse-checkout set examples/python/snippets/streaming/adk-streaming-ws
git checkout main
cd examples/python/snippets/streaming/adk-streaming-ws/app
此示例代码包含以下文件和文件夹:
adk-streaming-ws/
└── app/ # web 应用文件夹
├── .env # Gemini API 密钥 / Google Cloud 项目 ID
├── main.py # FastAPI web 应用
├── static/ # 静态内容文件夹
| ├── js # JavaScript 文件文件夹(包含 app.js)
| └── index.html # web 客户端页面
└── google_search_agent/ # 智能体文件夹
├── __init__.py # Python 包
└── agent.py # 智能体定义
2. 设置平台¶
要运行示例应用,请从 Google AI Studio 或 Google Cloud Vertex AI 中选择一个平台:
- 从 Google AI Studio 获取 API 密钥。
-
打开位于 (
app/) 内的.env文件,并复制粘贴以下代码。 -
将
PASTE_YOUR_ACTUAL_API_KEY_HERE替换为你的实际API KEY。
- 你需要一个现有的
Google Cloud 账户和一个项目。
- 设置一个 Google Cloud 项目
- 设置 gcloud CLI
- 通过在终端运行
gcloud auth login向 Google Cloud 进行身份验证。 - 启用 Vertex AI API。
-
打开位于 (
app/) 内的.env文件。复制粘贴 以下代码并更新项目 ID 和位置。
agent.py¶
google_search_agent 文件夹中的智能体定义代码 agent.py 是编写智能体逻辑的地方:
from google.adk.agents import Agent
from google.adk.tools import google_search # 导入工具
root_agent = Agent(
name="google_search_agent",
model="gemini-2.0-flash-exp", # 如果此模型不工作,请尝试下面的
#model="gemini-2.0-flash-live-001",
description="使用 Google 搜索回答问题的智能体。",
instruction="使用 Google 搜索工具回答问题。",
tools=[google_search],
)
注意: 要启用文本和音频/视频输入,模型必须支持 generateContent(用于文本)和 bidiGenerateContent 方法。通过参考 列表模型文档 来验证这些功能。此快速入门使用 gemini-2.0-flash-exp 模型进行演示。
注意你如何轻松集成 Google 搜索基础 功能。Agent 类和 google_search 工具处理与 LLM 的复杂交互以及与搜索 API 的基础,让你专注于智能体的 目的 和 行为。

3. 与你的流应用互动¶
- 导航到正确的目录:
要有效运行你的智能体,请确保你在 app 文件夹 (adk-streaming-ws/app) 中
- 启动 Fast API:运行以下命令启动 CLI 界面
- 以文本模式访问应用: 一旦应用启动,终端将显示一个本地 URL(例如 http://localhost:8000)。点击此链接在浏览器中打开 UI。
现在你应该看到如下所示的 UI:
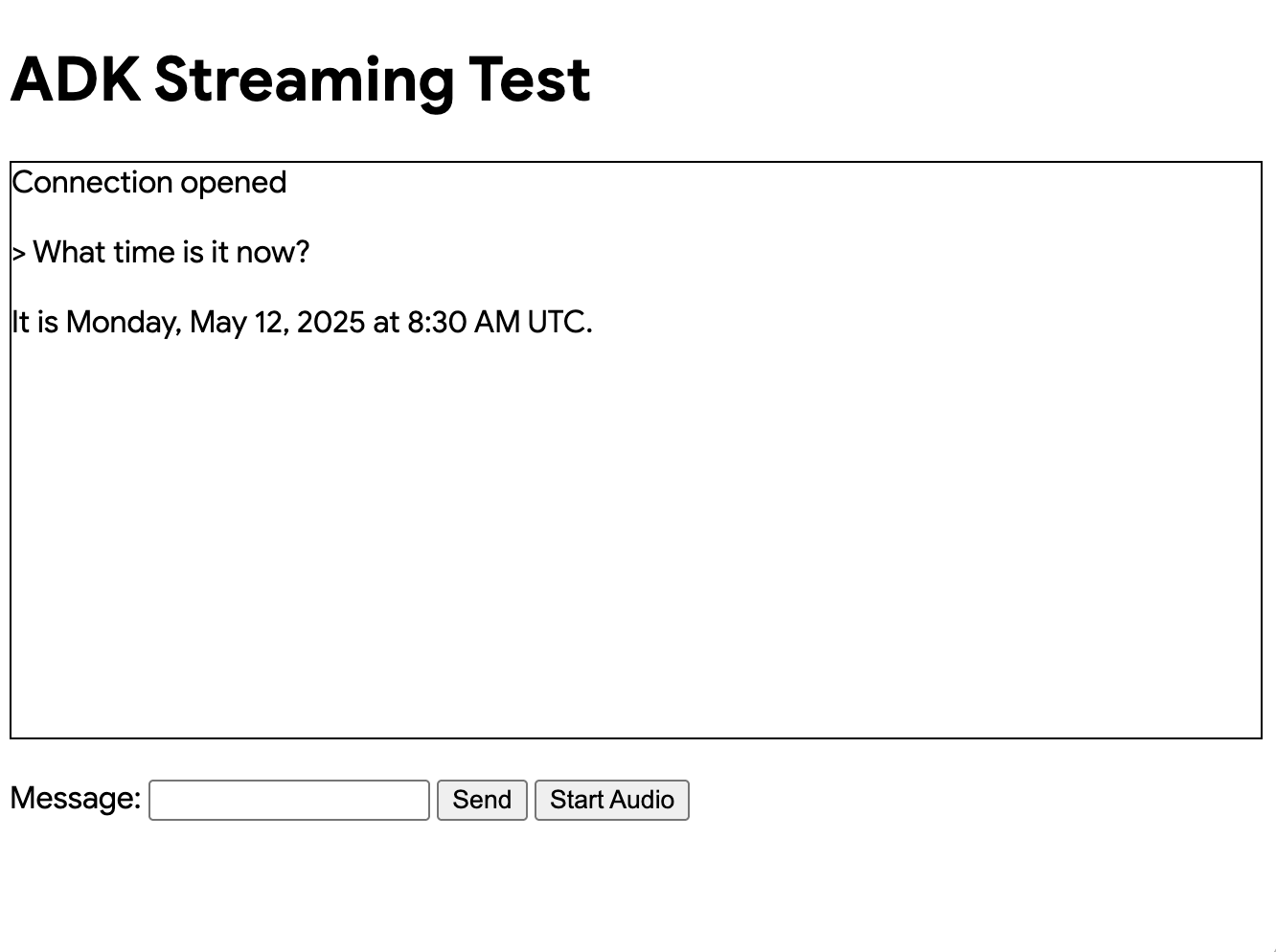
尝试提问 What time is it now?。智能体将使用 Google 搜索回应你的查询。你会注意到 UI 以流式文本显示智能体的回应。你也可以随时向智能体发送消息,即使智能体仍在回应中。这展示了 ADK Streaming 的双向通信能力。
- 以音频模式访问应用: 现在点击
Start Audio按钮。应用以音频模式重新连接服务器,首次使用时 UI 将显示以下对话框:
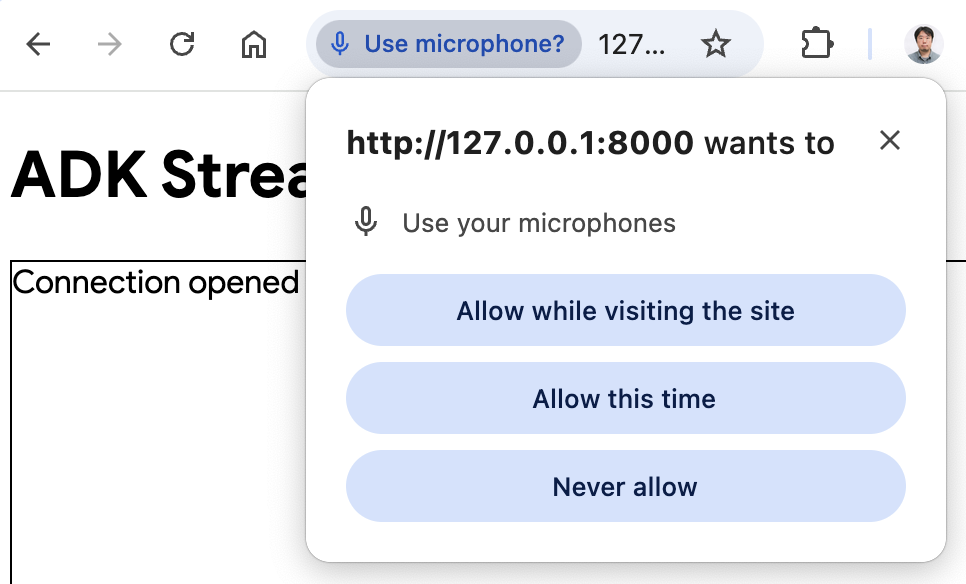
点击 Allow while visiting the site,然后你将看到麦克风图标显示在浏览器顶部:
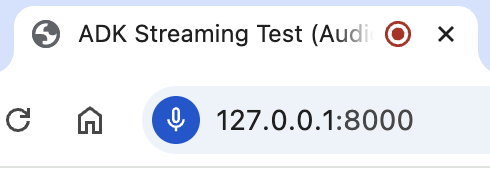
现在你可以用语音与智能体交谈。用语音提问类似 What time is it now? 的问题,你也会听到智能体用语音回应。由于 ADK 的 Streaming 支持 多种语言,它也可以用支持的语言回应问题。
- 查看控制台日志
如果你使用 Chrome 浏览器,右键点击并选择 Inspect 打开 DevTools。在 Console 中,你可以看到传入和传出的音频数据,例如 [CLIENT TO AGENT] 和 [AGENT TO CLIENT],表示浏览器和服务器之间流入和流出的音频数据。
同时,在应用服务器控制台中,你应该会看到类似这样的内容:
INFO: ('127.0.0.1', 50068) - "WebSocket /ws/70070018?is_audio=true" [accepted]
Client #70070018 connected, audio mode: true
INFO: connection open
INFO: 127.0.0.1:50061 - "GET /static/js/pcm-player-processor.js HTTP/1.1" 200 OK
INFO: 127.0.0.1:50060 - "GET /static/js/pcm-recorder-processor.js HTTP/1.1" 200 OK
[AGENT TO CLIENT]: audio/pcm: 9600 bytes.
INFO: 127.0.0.1:50082 - "GET /favicon.ico HTTP/1.1" 404 Not Found
[AGENT TO CLIENT]: audio/pcm: 11520 bytes.
[AGENT TO CLIENT]: audio/pcm: 11520 bytes.
如果你开发自己的流应用,这些控制台日志非常重要。在许多情况下,浏览器和服务器之间的通信失败是流应用 bug 的主要原因。
-
故障排除提示
-
当
ws://不工作时: 如果你在 Chrome DevTools 中看到关于ws://连接的任何错误,请尝试在app/static/js/app.js的第 28 行将ws://替换为wss://。当你在云环境中运行示例并使用代理连接从浏览器连接时可能会发生这种情况。 - 当
gemini-2.0-flash-exp模型不工作时: 如果你在应用服务器控制台中看到关于gemini-2.0-flash-exp模型可用性的任何错误,请尝试在app/google_search_agent/agent.py的第 6 行将其替换为gemini-2.0-flash-live-001。
4. 服务器代码概述¶
此服务器应用通过 WebSocket 实现与 ADK 智能体的实时、流式交互。客户端向 ADK 智能体发送文本/音频,并接收流式文本/音频响应。
核心功能: 1. 初始化/管理 ADK 智能体会话。 2. 处理客户端 WebSocket 连接。 3. 将客户端消息转发给 ADK 智能体。 4. 将 ADK 智能体响应(文本/音频)流式传输给客户端。
ADK Streaming 设置¶
import os
import json
import asyncio
import base64
from pathlib import Path
from dotenv import load_dotenv
from google.genai.types import (
Part,
Content,
Blob,
)
from google.adk.runners import Runner
from google.adk.agents import LiveRequestQueue
from google.adk.agents.run_config import RunConfig
from google.adk.sessions.in_memory_session_service import InMemorySessionService
from fastapi import FastAPI, WebSocket
from fastapi.staticfiles import StaticFiles
from fastapi.responses import FileResponse
from google_search_agent.agent import root_agent
- 导入: 包括标准 Python 库、用于环境变量的
dotenv、Google ADK 和 FastAPI。 load_dotenv(): 加载环境变量。APP_NAME:ADK 的应用标识符。session_service = InMemorySessionService():初始化内存中的 ADK 会话服务,适用于单实例或开发使用。生产环境可能使用持久化存储。
start_agent_session(session_id, is_audio=False)¶
async def start_agent_session(user_id, is_audio=False):
"""启动智能体会话"""
# 创建 Runner
runner = InMemoryRunner(
app_name=APP_NAME,
agent=root_agent,
)
# 创建会话
session = await runner.session_service.create_session(
app_name=APP_NAME,
user_id=user_id, # 替换为实际用户 ID
)
# 设置响应模态
modality = "AUDIO" if is_audio else "TEXT"
run_config = RunConfig(response_modalities=[modality])
# 为此会话创建 LiveRequestQueue
live_request_queue = LiveRequestQueue()
# 启动智能体会话
live_events = runner.run_live(
session=session,
live_request_queue=live_request_queue,
run_config=run_config,
)
return live_events, live_request_queue
此函数初始化 ADK 智能体实时会话。
| 参数 | 类型 | 描述 |
|---|---|---|
user_id |
str |
唯一客户端标识符。 |
is_audio |
bool |
音频响应为 True,文本响应为 False(默认)。 |
关键步骤:
1. 创建 Runner: 为 root_agent 实例化 ADK 运行器。
2. 创建会话: 建立 ADK 会话。
3. 设置响应模态: 将智能体响应配置为 "AUDIO" 或 "TEXT"。
4. 创建 LiveRequestQueue: 为客户端输入到智能体创建队列。
5. 启动智能体会话: runner.run_live(...) 启动智能体,返回:
* live_events:智能体事件的异步可迭代对象(文本、音频、完成)。
* live_request_queue:向智能体发送数据的队列。
返回: (live_events, live_request_queue)。
agent_to_client_messaging(websocket, live_events)¶
async def agent_to_client_messaging(websocket, live_events):
"""智能体到客户端的通信"""
while True:
async for event in live_events:
# 如果轮次完成或中断,发送它
if event.turn_complete or event.interrupted:
message = {
"turn_complete": event.turn_complete,
"interrupted": event.interrupted,
}
await websocket.send_text(json.dumps(message))
print(f"[AGENT TO CLIENT]: {message}")
continue
# 读取内容和其第一个部分
part: Part = (
event.content and event.content.parts and event.content.parts[0]
)
if not part:
continue
# 如果是音频,发送 Base64 编码的音频数据
is_audio = part.inline_data and part.inline_data.mime_type.startswith("audio/pcm")
if is_audio:
audio_data = part.inline_data and part.inline_data.data
if audio_data:
message = {
"mime_type": "audio/pcm",
"data": base64.b64encode(audio_data).decode("ascii")
}
await websocket.send_text(json.dumps(message))
print(f"[AGENT TO CLIENT]: audio/pcm: {len(audio_data)} bytes.")
continue
# 如果是文本且是部分文本,发送它
if part.text and event.partial:
message = {
"mime_type": "text/plain",
"data": part.text
}
await websocket.send_text(json.dumps(message))
print(f"[AGENT TO CLIENT]: text/plain: {message}")
此异步函数将 ADK 智能体事件流式传输到 WebSocket 客户端。
逻辑:
1. 迭代来自智能体的 live_events。
2. 轮次完成/中断: 向客户端发送状态标志。
3. 内容处理:
* 从事件内容中提取第一个 Part。
* 音频数据: 如果是音频(PCM),进行 Base64 编码并作为 JSON 发送:{ "mime_type": "audio/pcm", "data": "<base64_audio>" }。
* 文本数据: 如果是部分文本,作为 JSON 发送:{ "mime_type": "text/plain", "data": "<partial_text>" }。
4. 记录消息。
client_to_agent_messaging(websocket, live_request_queue)¶
async def client_to_agent_messaging(websocket, live_request_queue):
"""客户端到智能体的通信"""
while True:
# 解码 JSON 消息
message_json = await websocket.receive_text()
message = json.loads(message_json)
mime_type = message["mime_type"]
data = message["data"]
# 将消息发送给智能体
if mime_type == "text/plain":
# 发送文本消息
content = Content(role="user", parts=[Part.from_text(text=data)])
live_request_queue.send_content(content=content)
print(f"[CLIENT TO AGENT]: {data}")
elif mime_type == "audio/pcm":
# 发送音频数据
decoded_data = base64.b64decode(data)
live_request_queue.send_realtime(Blob(data=decoded_data, mime_type=mime_type))
else:
raise ValueError(f"Mime type not supported: {mime_type}")
此异步函数将来自 WebSocket 客户端的消息转发给 ADK 智能体。
逻辑:
1. 接收并解析来自 WebSocket 的 JSON 消息,期望:{ "mime_type": "text/plain" | "audio/pcm", "data": "<data>" }。
2. 文本输入: 对于 "text/plain",通过 live_request_queue.send_content() 向智能体发送 Content。
3. 音频输入: 对于 "audio/pcm",解码 Base64 数据,包装在 Blob 中,并通过 live_request_queue.send_realtime() 发送。
4. 对不支持的 MIME 类型抛出 ValueError。
5. 记录消息。
FastAPI Web 应用¶
app = FastAPI()
STATIC_DIR = Path("static")
app.mount("/static", StaticFiles(directory=STATIC_DIR), name="static")
@app.get("/")
async def root():
"""提供 index.html"""
return FileResponse(os.path.join(STATIC_DIR, "index.html"))
@app.websocket("/ws/{user_id}")
async def websocket_endpoint(websocket: WebSocket, user_id: int, is_audio: str):
"""客户端 websocket 端点"""
# 等待客户端连接
await websocket.accept()
print(f"Client #{user_id} connected, audio mode: {is_audio}")
# 启动智能体会话
user_id_str = str(user_id)
live_events, live_request_queue = await start_agent_session(user_id_str, is_audio == "true")
# 启动任务
agent_to_client_task = asyncio.create_task(
agent_to_client_messaging(websocket, live_events)
)
client_to_agent_task = asyncio.create_task(
client_to_agent_messaging(websocket, live_request_queue)
)
# 等待直到 websocket 断开连接或发生错误
tasks = [agent_to_client_task, client_to_agent_task]
await asyncio.wait(tasks, return_when=asyncio.FIRST_EXCEPTION)
# 关闭 LiveRequestQueue
live_request_queue.close()
# 断开连接
print(f"Client #{user_id} disconnected")
app = FastAPI():初始化应用。- 静态文件: 在
/static下提供static目录中的文件。 @app.get("/")(根端点): 提供index.html。@app.websocket("/ws/{user_id}")(WebSocket 端点):- 路径参数:
user_id(int)和is_audio(str:"true"/"false")。 - 连接处理:
- 接受 WebSocket 连接。
- 使用
user_id和is_audio调用start_agent_session()。 - 并发消息任务: 使用
asyncio.gather并发创建和运行agent_to_client_messaging和client_to_agent_messaging。这些任务处理双向消息流。 - 记录客户端连接和断开连接。
- 路径参数:
工作原理(整体流程){#how-it-works-overall-flow}¶
- 客户端连接到
ws://<server>/ws/<user_id>?is_audio=<true_or_false>。 - 服务器的
websocket_endpoint接受,启动 ADK 会话(start_agent_session)。 - 两个
asyncio任务管理通信:client_to_agent_messaging:客户端 WebSocket 消息 -> ADKlive_request_queue。agent_to_client_messaging:ADKlive_events-> 客户端 WebSocket。
- 双向流式传输持续进行,直到断开连接或错误。
5. 客户端代码概述¶
JavaScript app.js(在 app/static/js 中)管理客户端与 ADK Streaming WebSocket 后端的交互。它处理发送文本/音频和接收/显示流式响应。
关键功能: 1. 管理 WebSocket 连接。 2. 处理文本输入。 3. 捕获麦克风音频(Web Audio API,AudioWorklets)。 4. 向后端发送文本/音频。 5. 接收和渲染文本/音频智能体响应。 6. 管理 UI。
前提条件¶
- HTML 结构: 需要特定的元素 ID(例如
messageForm、message、messages、sendButton、startAudioButton)。 - 后端服务器: Python FastAPI 服务器必须运行。
- 音频工作节点文件: 用于音频处理的
audio-player.js和audio-recorder.js。
WebSocket 处理¶
// 使用 WebSocket 连接连接服务器
const sessionId = Math.random().toString().substring(10);
const ws_url =
"ws://" + window.location.host + "/ws/" + sessionId;
let websocket = null;
let is_audio = false;
// 获取 DOM 元素
const messageForm = document.getElementById("messageForm");
const messageInput = document.getElementById("message");
const messagesDiv = document.getElementById("messages");
let currentMessageId = null;
// WebSocket 处理程序
function connectWebsocket() {
// 连接 websocket
websocket = new WebSocket(ws_url + "?is_audio=" + is_audio);
// 处理连接打开
websocket.onopen = function () {
// 连接打开消息
console.log("WebSocket connection opened.");
document.getElementById("messages").textContent = "Connection opened";
// 启用发送按钮
document.getElementById("sendButton").disabled = false;
addSubmitHandler();
};
// 处理传入消息
websocket.onmessage = function (event) {
// 解析传入消息
const message_from_server = JSON.parse(event.data);
console.log("[AGENT TO CLIENT] ", message_from_server);
// 检查轮次是否完成
// 如果轮次完成,添加新消息
if (
message_from_server.turn_complete &&
message_from_server.turn_complete == true
) {
currentMessageId = null;
return;
}
// 如果是音频,播放它
if (message_from_server.mime_type == "audio/pcm" && audioPlayerNode) {
audioPlayerNode.port.postMessage(base64ToArray(message_from_server.data));
}
// 如果是文本,打印它
if (message_from_server.mime_type == "text/plain") {
// 为新轮次添加新消息
if (currentMessageId == null) {
currentMessageId = Math.random().toString(36).substring(7);
const message = document.createElement("p");
message.id = currentMessageId;
// 将消息元素附加到 messagesDiv
messagesDiv.appendChild(message);
}
// 将消息文本添加到现有消息元素
const message = document.getElementById(currentMessageId);
message.textContent += message_from_server.data;
// 向下滚动到 messagesDiv 底部
messagesDiv.scrollTop = messagesDiv.scrollHeight;
}
};
// 处理连接关闭
websocket.onclose = function () {
console.log("WebSocket connection closed.");
document.getElementById("sendButton").disabled = true;
document.getElementById("messages").textContent = "Connection closed";
setTimeout(function () {
console.log("Reconnecting...");
connectWebsocket();
}, 5000);
};
websocket.onerror = function (e) {
console.log("WebSocket error: ", e);
};
}
connectWebsocket();
// 向表单添加提交处理程序
function addSubmitHandler() {
messageForm.onsubmit = function (e) {
e.preventDefault();
const message = messageInput.value;
if (message) {
const p = document.createElement("p");
p.textContent = "> " + message;
messagesDiv.appendChild(p);
messageInput.value = "";
sendMessage({
mime_type: "text/plain",
data: message,
});
console.log("[CLIENT TO AGENT] " + message);
}
return false;
};
}
// 向服务器发送消息作为 JSON 字符串
function sendMessage(message) {
if (websocket && websocket.readyState == WebSocket.OPEN) {
const messageJson = JSON.stringify(message);
websocket.send(messageJson);
}
}
// 将 Base64 数据解码为数组
function base64ToArray(base64) {
const binaryString = window.atob(base64);
const len = binaryString.length;
const bytes = new Uint8Array(len);
for (let i = 0; i < len; i++) {
bytes[i] = binaryString.charCodeAt(i);
}
return bytes.buffer;
}
- 连接设置: 生成
sessionId,构造ws_url。is_audio标志(初始为false)在活跃时向 URL 追加?is_audio=true。connectWebsocket()初始化连接。 websocket.onopen:启用发送按钮,更新 UI,调用addSubmitHandler()。websocket.onmessage:解析来自服务器的传入 JSON。- 轮次完成: 如果智能体轮次完成,重置
currentMessageId。 - 音频数据(
audio/pcm): 解码 Base64 音频(base64ToArray())并发送到audioPlayerNode进行播放。 - 文本数据(
text/plain): 如果是新轮次(currentMessageId为 null),创建新<p>。将接收到的文本附加到当前消息段落以实现流式效果。滚动messagesDiv。
- 轮次完成: 如果智能体轮次完成,重置
websocket.onclose:禁用发送按钮,更新 UI,5 秒后尝试自动重连。websocket.onerror:记录错误。- 初始连接: 脚本加载时调用
connectWebsocket()。
DOM 交互和消息提交¶
- 元素检索: 获取所需的 DOM 元素。
addSubmitHandler():附加到messageForm的提交。阻止默认提交,从messageInput获取文本,显示用户消息,清除输入,并使用{ mime_type: "text/plain", data: messageText }调用sendMessage()。sendMessage(messagePayload):如果 WebSocket 打开,发送 JSON 字符串化的messagePayload。
音频处理¶
let audioPlayerNode;
let audioPlayerContext;
let audioRecorderNode;
let audioRecorderContext;
let micStream;
// 导入音频工作节点
import { startAudioPlayerWorklet } from "./audio-player.js";
import { startAudioRecorderWorklet } from "./audio-recorder.js";
// 启动音频
function startAudio() {
// 启动音频输出
startAudioPlayerWorklet().then(([node, ctx]) => {
audioPlayerNode = node;
audioPlayerContext = ctx;
});
// 启动音频输入
startAudioRecorderWorklet(audioRecorderHandler).then(
([node, ctx, stream]) => {
audioRecorderNode = node;
audioRecorderContext = ctx;
micStream = stream;
}
);
}
// 仅当用户点击按钮时启动音频
// (由于 Web Audio API 的手势要求)
const startAudioButton = document.getElementById("startAudioButton");
startAudioButton.addEventListener("click", () => {
startAudioButton.disabled = true;
startAudio();
is_audio = true;
connectWebsocket(); // 以音频模式重新连接
});
// 音频录制器处理程序
function audioRecorderHandler(pcmData) {
// 以 base64 发送 pcm 数据
sendMessage({
mime_type: "audio/pcm",
data: arrayBufferToBase64(pcmData),
});
console.log("[CLIENT TO AGENT] sent %s bytes", pcmData.byteLength);
}
// 使用 Base64 编码数组缓冲区
function arrayBufferToBase64(buffer) {
let binary = "";
const bytes = new Uint8Array(buffer);
const len = bytes.byteLength;
for (let i = 0; i < len; i++) {
binary += String.fromCharCode(bytes[i]);
}
return window.btoa(binary);
}
- 音频工作节点: 通过
audio-player.js(用于播放)和audio-recorder.js(用于捕获)使用AudioWorkletNode。 - 状态变量: 存储 AudioContext 和 WorkletNode(例如
audioPlayerNode)。 startAudio():初始化播放器和录制器工作节点。将audioRecorderHandler作为回调传递给录制器。- "Start Audio" 按钮(
startAudioButton):- Web Audio API 需要用户手势。
- 点击时:禁用按钮,调用
startAudio(),设置is_audio = true,然后调用connectWebsocket()以音频模式重新连接(URL 包含?is_audio=true)。
audioRecorderHandler(pcmData):来自录制器工作节点的回调,包含 PCM 音频块。将pcmData编码为 Base64(arrayBufferToBase64())并通过带有mime_type: "audio/pcm"的sendMessage()发送到服务器。- 辅助函数:
base64ToArray()(服务器音频 -> 客户端播放器)和arrayBufferToBase64()(客户端麦克风音频 -> 服务器)。
工作原理(客户端流程){#how-it-works-client-side-flow}¶
- 页面加载: 在文本模式下建立 WebSocket。
- 文本交互: 用户输入/提交文本;发送到服务器。显示服务器文本响应,流式传输。
- 切换到音频模式: "Start Audio" 按钮点击初始化音频工作节点,设置
is_audio=true,并在音频模式下重新连接 WebSocket。 - 音频交互: 录制器向服务器发送麦克风音频(Base64 PCM)。服务器音频/文本响应由
websocket.onmessage处理,用于播放/显示。 - 连接管理: WebSocket 关闭时自动重连。
总结¶
本文概述了使用 ADK Streaming 和 FastAPI 构建的自定义异步 web 应用的服务器和客户端代码,实现实时、双向语音和文本通信。
Python FastAPI 服务器代码初始化 ADK 智能体会话,配置为文本或音频响应。它使用 WebSocket 端点处理客户端连接。异步任务管理双向消息传递:将客户端文本或 Base64 编码的 PCM 音频转发给 ADK 智能体,并将来自智能体的文本或 Base64 编码的 PCM 音频响应流式传输回客户端。
客户端 JavaScript 代码管理 WebSocket 连接,可以重新建立以在文本和音频模式之间切换。它将用户输入(文本或通过 Web Audio API 和 AudioWorklet 捕获的麦克风音频)发送到服务器。来自服务器的传入消息被处理:显示文本(流式),使用 AudioWorklet 解码和播放 Base64 编码的 PCM 音频。
生产环境的后续步骤¶
当你在生产应用中使用 ADK Streaming 时,你可能需要考虑以下几点:
- 部署多个实例: 运行 FastAPI 应用的多个实例,而不是单个实例。
- 实施负载均衡: 在应用实例前放置负载均衡器,以分发传入的 WebSocket 连接。
- 为 WebSocket 配置: 确保负载均衡器支持长期存在的 WebSocket 连接,并考虑"粘性会话"(会话亲和性)将客户端路由到同一后端实例,或者 设计无状态实例(见下一点)。
- 外部化会话状态: 用分布式、持久的会话存储替换 ADK 的
InMemorySessionService。这允许任何服务器实例处理任何用户的会话,在应用服务器级别实现真正的无状态性,并提高容错能力。 - 实施健康检查: 为你的 WebSocket 服务器实例设置健壮的健康检查,以便负载均衡器可以自动从轮换中移除不健康的实例。
- 利用编排: 考虑使用编排平台(如 Kubernetes)来自动部署、扩展、自愈和管理你的 WebSocket 服务器实例。