为什么要评估智能体?¶
在传统软件开发中,单元测试和集成测试提供了代码按预期运行并在变更中保持稳定的信心。这些测试提供了明确的"通过/失败"信号,指导进一步的开发。然而,LLM 智能体引入了一定程度的变异性,使得传统的测试方法不够充分。
由于模型的概率性特质,确定性的"通过/失败"断言通常不适合评估智能体性能。相反,我们需要对最终输出和智能体轨迹(达成解决方案所采取的步骤序列)进行定性评估。这涉及评估智能体决策的质量、推理过程以及最终结果。
这看起来可能需要额外的工作量来搭建,但自动化评估的投入很快就会得到回报。如果你打算超越原型阶段,这是一个强烈推荐的最佳实践。
准备智能体评估¶
在自动化智能体评估之前,定义明确的目标和成功标准:
- 定义成功: 什么构成了你的智能体的成功结果?
- 识别关键任务: 你的智能体必须完成哪些基本任务?
- 选择相关指标: 你将跟踪哪些指标来衡量性能?
这些考虑因素将指导评估场景的创建,并能够有效监控智能体在真实部署中的行为。
评估什么?¶
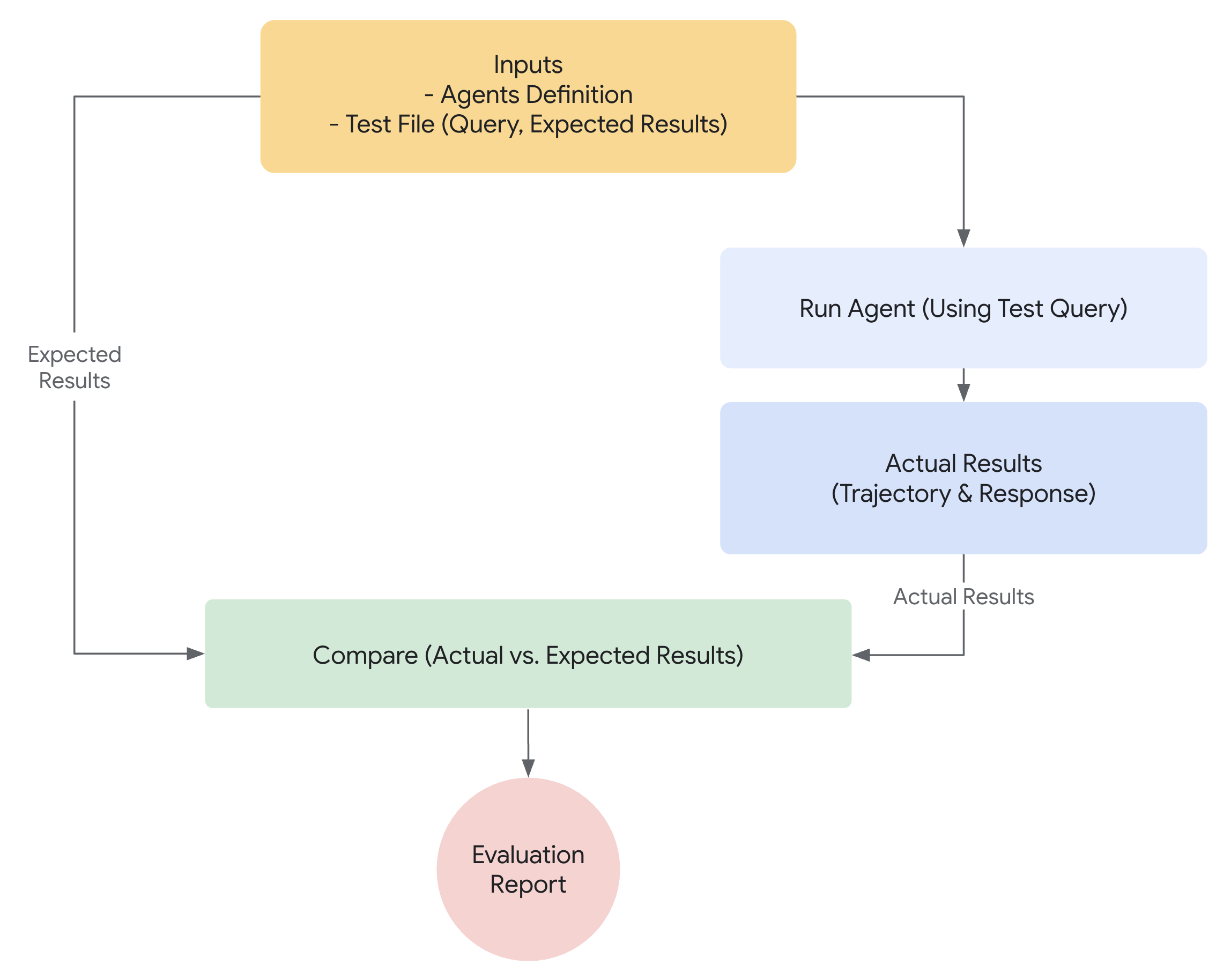
要从概念验证过渡到生产就绪的 AI 智能体,一个强大且自动化的评估框架至关重要。与评估生成式模型不同(主要关注最终输出),智能体评估需要更深入地理解决策过程。智能体评估可以分为两个组成部分:
- 评估轨迹和工具使用: 分析智能体达成解决方案所采取的步骤,包括其工具选择、策略以及方法的效率。
- 评估最终响应: 评估智能体最终输出的质量、相关性和正确性。
轨迹只是智能体在返回给用户之前所采取的步骤列表。我们可以将其与我们期望智能体采取的步骤列表进行比较。
评估轨迹和工具使用¶
在响应用户之前,智能体通常会执行一系列操作,我们称之为"轨迹"。它可能会将用户输入与会话历史进行比较以消除术语歧义,或查阅政策文档、搜索知识库或调用 API 来保存工单。我们称这一系列操作为行动"轨迹"。评估智能体的性能需要将其实际轨迹与预期或理想轨迹进行比较。这种比较可以揭示智能体过程中的错误和低效之处。预期轨迹代表了基准事实——我们预计智能体应该采取的步骤列表。
例如:
# 轨迹评估将比较
expected_steps = ["determine_intent", "use_tool", "review_results", "report_generation"]
actual_steps = ["determine_intent", "use_tool", "review_results", "report_generation"]
ADK 提供了基于基准事实和基于评分标准的工具使用评估指标。要为你的智能体的特定需求和目标选择合适的指标,请参阅我们的建议。
ADK 中评估如何工作¶
ADK 提供了两种方法来根据预定义的数据集和评估标准评估智能体性能。虽然概念上相似,但它们在能处理的数据量上有所不同,这通常决定了每种方法的适用场景。
第一种方法:使用测试文件¶
这种方法涉及创建单独的测试文件,每个文件代表一个简单的智能体 - 模型交互(一个会话)。它在活跃的智能体开发阶段最有效,作为单元测试的一种形式。这些测试旨在快速执行,应专注于简单的会话复杂性。每个测试文件包含单个会话,而会话可能包含多个轮次。一个轮次代表用户和智能体之间的单次交互。每个轮次包括:
User Content: 用户发出的查询。Expected Intermediate Tool Use Trajectory: 我们期望智能体为正确响应用户查询而进行的工具调用。Expected Intermediate Agent Responses: 这些是智能体(或子智能体)在生成最终答案过程中产生的自然语言响应。这些自然语言响应通常是多智能体系统的产物,其中你的根智能体依赖子智能体来实现目标。这些中间响应对于终端用户来说可能并不重要,但对于系统开发者/拥有者来说至关重要,因为它们能让你确信智能体走对了生成最终响应的路径。Final Response: 智能体的预期最终响应。
你可以给文件任何名称,例如 evaluation.test.json。框架只检查 .test.json 后缀,文件名前面的部分不受限制。测试文件由正式的 Pydantic 数据模型支持。两个关键的 schema 文件是 Eval Set 和 Eval Case。
以下是包含几个示例的测试文件:
(注意:包含注释是为了解释目的,应该删除以使 JSON 有效。)
# 请注意,为了使本文档可读,删除了一些字段。
{
"eval_set_id": "home_automation_agent_light_on_off_set",
"name": "",
"description": "这是一个用于单元测试智能体 `x` 行为的评估集",
"eval_cases": [
{
"eval_id": "eval_case_id",
"conversation": [
{
"invocation_id": "b7982664-0ab6-47cc-ab13-326656afdf75", # 调用的唯一标识符。
"user_content": { # 用户在此调用中提供的内容。这是查询。
"parts": [
{
"text": "关闭卧室的 device_2。"
}
],
"role": "user"
},
"final_response": { # 智能体的最终响应,作为基准参考。
"parts": [
{
"text": "我已将 device_2 状态设置为关闭。"
}
],
"role": "model"
},
"intermediate_data": {
"tool_uses": [ # 按时间顺序排列的工具使用轨迹。
{
"args": {
"location": "Bedroom",
"device_id": "device_2",
"status": "OFF"
},
"name": "set_device_info"
}
],
"intermediate_responses": [] # 任何中间子智能体响应。
},
}
],
"session_input": { # 初始会话输入。
"app_name": "home_automation_agent",
"user_id": "test_user",
"state": {}
}
}
]
}
测试文件可以组织到文件夹中。可选地,文件夹还可以包含一个test_config.json文件,指定评估标准。
如何迁移未遵循 Pydantic schema 的评测集文件?¶
注意:如果你的评测集文件没有遵循 EvalSet schema 文件,那么本节内容与你相关。
请使用 AgentEvaluator.migrate_eval_data_to_new_schema 来将你现有的 *.test.json 文件迁移到 Pydantic 支持的 schema。
-
由 ADK UI 维护的评测集数据 如果你使用 ADK UI 维护评测集数据,那么你无需采取任何操作。
-
评测集数据由你手动开发和维护,并在 ADK eval Cli 中使用 迁移工具正在开发中,在此之前,ADK eval cli 命令会继续支持旧格式的数据。
第二种方法:使用评估集文件¶
评估集文件包含多个“评估”,每个代表一个不同的会话。每个评估由一个或多个“轮次”组成,其中包括用户查询、预期的工具使用、预期的中间智能体响应和参考响应。这些字段的含义与测试文件方法中的相同。或者,一个评估可以定义一个对话场景,用于动态模拟用户与智能体的交互。每个评估由一个唯一的名称标识。此外,每个评估都包含一个关联的初始会话状态。
手动创建评估集可能很复杂,因此提供了 UI 工具来帮助捕获相关会话并轻松将其转换为评估集中的评估。在下面了解更多关于使用 Web UI 进行评估的信息。以下是包含两个会话的评估集示例。评估集文件由正式的 Pydantic 数据模型支持。两个关键的 schema 文件是 Eval Set 和 Eval Case。
Warning
此评估集评估方法需要使用付费服务, Vertex Gen AI Evaluation Service API。
(注意:包含注释是为了解释目的,应该删除以使 JSON 有效。)
# 请注意,为了使本文档可读,删除了一些字段。
{
"eval_set_id": "eval_set_example_with_multiple_sessions",
"name": "包含多个会话的评估集",
"description": "这个评估集是一个示例,显示评估集可以有多个会话。",
"eval_cases": [
{
"eval_id": "session_01",
"conversation": [
{
"invocation_id": "e-0067f6c4-ac27-4f24-81d7-3ab994c28768",
"user_content": {
"parts": [
{
"text": "你能做什么?"
}
],
"role": "user"
},
"final_response": {
"parts": [
{
"text": "我可以掷不同大小的骰子并检查数字是否为质数。"
}
],
"role": null
},
"intermediate_data": {
"tool_uses": [],
"intermediate_responses": []
}
}
],
"session_input": {
"app_name": "hello_world",
"user_id": "user",
"state": {}
}
},
{
"eval_id": "session_02",
"conversation": [
{
"invocation_id": "e-92d34c6d-0a1b-452a-ba90-33af2838647a",
"user_content": {
"parts": [
{
"text": "掷一个 19 面骰子"
}
],
"role": "user"
},
"final_response": {
"parts": [
{
"text": "我掷出了 17。"
}
],
"role": null
},
"intermediate_data": {
"tool_uses": [],
"intermediate_responses": []
}
},
{
"invocation_id": "e-bf8549a1-2a61-4ecc-a4ee-4efbbf25a8ea",
"user_content": {
"parts": [
{
"text": "掷两次 10 面骰子,然后检查 9 是否为质数"
}
],
"role": "user"
},
"final_response": {
"parts": [
{
"text": "我从掷骰子中得到了 4 和 7,9 不是质数。\n"
}
],
"role": null
},
"intermediate_data": {
"tool_uses": [
{
"id": "adk-1a3f5a01-1782-4530-949f-07cf53fc6f05",
"args": {
"sides": 10
},
"name": "roll_die"
},
{
"id": "adk-52fc3269-caaf-41c3-833d-511e454c7058",
"args": {
"sides": 10
},
"name": "roll_die"
},
{
"id": "adk-5274768e-9ec5-4915-b6cf-f5d7f0387056",
"args": {
"nums": [
9
]
},
"name": "check_prime"
}
],
"intermediate_responses": [
[
"data_processing_agent",
[
{
"text": "我已经掷了两次 10 面骰子。第一次掷出 4,第二次掷出 7。\n"
}
]
]
]
}
}
],
"session_input": {
"app_name": "hello_world",
"user_id": "user",
"state": {}
}
}
]
}
如何迁移未遵循 Pydantic schema 的评估集文件?¶
注意:如果你的评估集文件没有遵循 EvalSet schema 文件,那么本节内容与你相关。
根据谁在维护评估集数据,有两种方式:
-
由 ADK UI 维护的评估集数据 如果你使用 ADK UI 维护评估集数据,那么你无需采取任何操作。
-
评估集数据由你手动开发和维护,并在 ADK eval CLI 中使用 迁移工具正在开发中,在此之前,ADK eval CLI 命令会继续支持旧格式的数据。
评估标准¶
ADK 提供了多种内置标准来评估智能体性能,范围从工具轨迹匹配到基于 LLM 的响应质量评估。有关可用标准的详细列表以及何时使用它们的指南,请参阅评估标准。
以下是所有可用标准的摘要:
- tool_trajectory_avg_score: 工具调用轨迹的精确匹配。
- response_match_score: 与参考响应的 ROUGE-1 相似度。
- final_response_match_v2: LLM 评判的与参考响应的语义匹配。
- rubric_based_final_response_quality_v1: 基于自定义评分标准的 LLM 评判的最终响应质量。
- rubric_based_tool_use_quality_v1: 基于自定义评分标准的 LLM 评判的工具使用质量。
- hallucinations_v1: LLM 评判的智能体响应与上下文的一致性。
- safety_v1: 智能体响应的安全性/无害性。
如果没有提供评估标准,将使用以下默认配置:
tool_trajectory_avg_score: 默认为 1.0,要求工具使用轨迹 100% 匹配。response_match_score: 默认为 0.8,允许智能体的自然语言响应有小误差。
以下是指定自定义评估标准的test_config.json文件示例:
标准选择建议¶
根据你的评估目标选择标准:
- 在 CI/CD 流水线或回归测试中启用测试: 使用
tool_trajectory_avg_score和response_match_score。这些标准快速、可预测,适合频繁的自动化检查。 - 评估可信的参考响应: 使用
final_response_match_v2来评估语义等价性。这种基于 LLM 的检查比精确匹配更灵活,并且更好地捕获智能体的响应是否与参考响应表示相同含义。 - 在没有参考响应的情况下评估响应质量: 使用
rubric_based_final_response_quality_v1。当你没有可信的参考时这很有用,但你可以定义良好响应的属性(例如,“响应简洁”,“响应有帮助的语调”)。 - 评估工具使用的正确性: 使用
rubric_based_tool_use_quality_v1。这允许你通过验证特定工具是否被调用或工具是否按正确顺序调用(例如,“工具 A 必须在工具 B 之前调用”)来验证智能体的推理过程。 - 检查响应是否基于上下文: 使用
hallucinations_v1来检测智能体是否提出无支撑或与可用信息相矛盾的声明(例如,工具输出)。 - 检查有害内容: 使用
safety_v1确保智能体响应安全且不违反安全策略。
此外,需要有关预期智能体工具使用和/或响应信息的标准不支持与用户模拟结合使用。目前,只有 hallucinations_v1 和 safety_v1 标准支持此类评估。
用户模拟¶
在评估对话式智能体时,使用固定的用户提示集并不总是可行的,因为对话可能会以意想不到的方式进行。例如,如果智能体需要用户提供两个值来执行任务,它可能会一次请求一个值或一次请求两个值。为了解决这个问题,ADK 允许你使用由 AI 模型动态生成的用户提示,在特定的对话场景中测试智能体的行为。有关如何设置带用户模拟的评估的详细信息,请参阅用户模拟。
如何使用 ADK 运行评估¶
作为开发者,你可以通过以下方式使用 ADK 评估你的智能体:
- 基于 Web 的 UI(
adk web): 通过基于 Web 的界面交互式评估智能体。 - 编程方式(
pytest): 使用pytest和测试文件将评估集成到你的测试流程中。 - 命令行界面(
adk eval): 直接从命令行对现有评估集文件运行评估。
1. adk web - 通过 Web UI 运行评估¶
Web UI 提供了一种交互式的方式来评估智能体、生成评估数据集,并详细检查智能体行为。
第一步:创建并保存测试用例¶
- 运行以下命令启动 Web 服务器:
adk web <path_to_your_agents_folder> - 在 Web 界面中,选择一个智能体并与其交互以创建会话。
- 导航到界面右侧的 Eval 选项卡。
- 创建新的评估集或选择现有的评估集。
- 点击 "Add current session" 将对话保存为新的评估用例。
第二步:查看和编辑你的测试用例¶
保存用例后,你可以点击列表中的 ID 来检查它。要进行更改,请点击 Edit current eval case 图标(铅笔)。这个交互式视图允许你:
- 修改 智能体文本响应以完善测试场景。
- 删除 对话中的单个智能体消息。
- 删除 整个评估用例(如果不再需要)。
第三步:使用自定义指标运行评估¶
- 从你的评估集中选择一个或多个测试用例。
- 点击 Run Evaluation。会出现一个 EVALUATION METRIC 对话框。
- 在对话框中,使用滑块配置以下阈值:
- Tool trajectory avg score
- Response match score
- 点击 Start 使用你的自定义标准运行评估。评估历史将记录每次运行使用的指标。
第四步:分析结果¶
运行完成后,你可以分析结果:
- 分析运行失败:点击任何 Pass 或 Fail 结果。对于失败的情况,你可以将鼠标悬停在
Fail标签上,以查看 实际输出与期望输出 的并排比较,以及导致失败的分数。
使用跟踪视图进行调试¶
ADK Web UI 包含一个强大的 Trace 选项卡,用于调试智能体行为。此功能适用于任何智能体会话,不仅仅在评估期间可用。
Trace 选项卡提供了一种详细和交互式的方式来检查你的智能体执行流程。跟踪自动按用户消息分组,便于跟踪事件链。
每个跟踪行都是交互式的:
- 悬停 在跟踪行上会在聊天窗口中突出显示相应的消息。
- 点击 跟踪行会打开一个详细的检查面板,包含四个选项卡:
- Event:原始事件数据。
- Request:发送到模型的请求。
- Response:从模型接收的响应。
- Graph:工具调用和智能体逻辑流程的可视化表示。
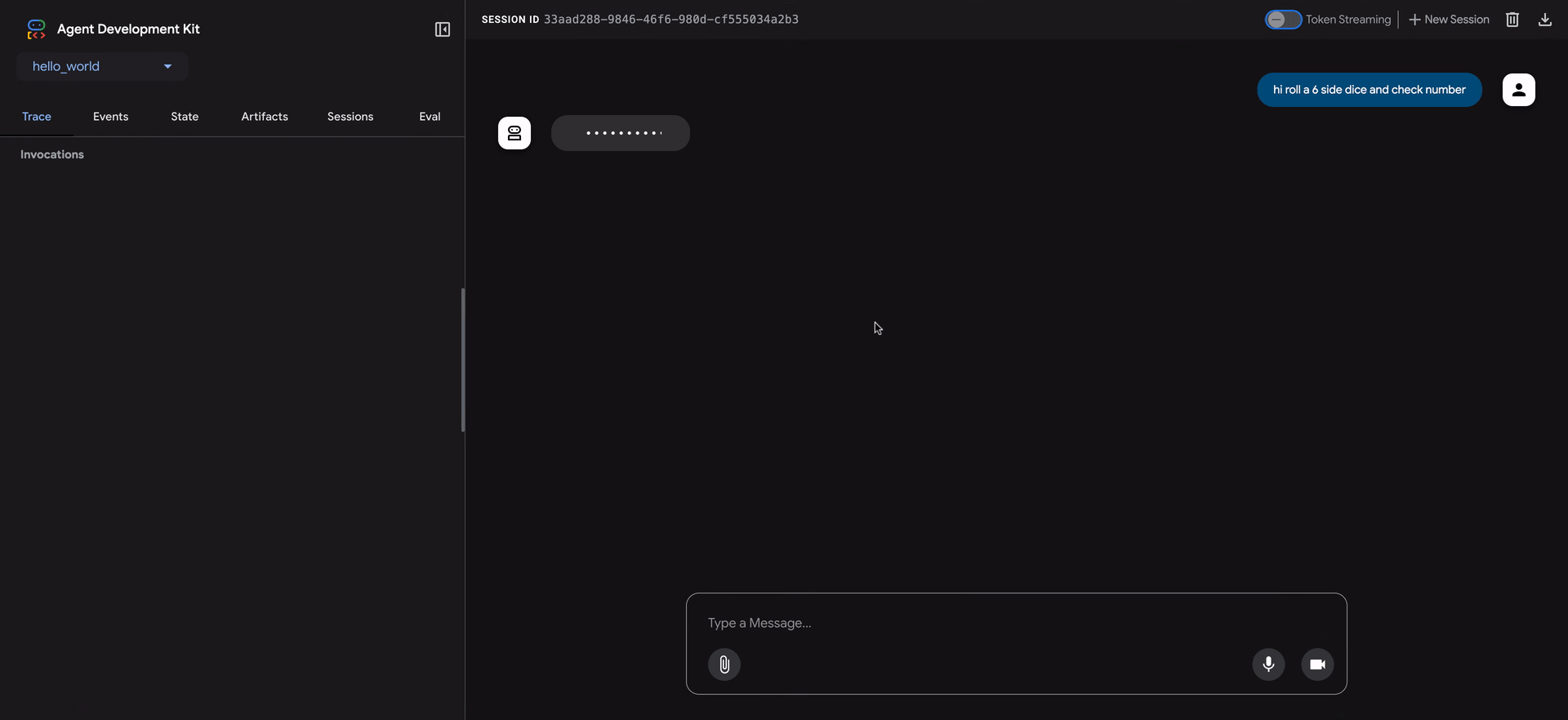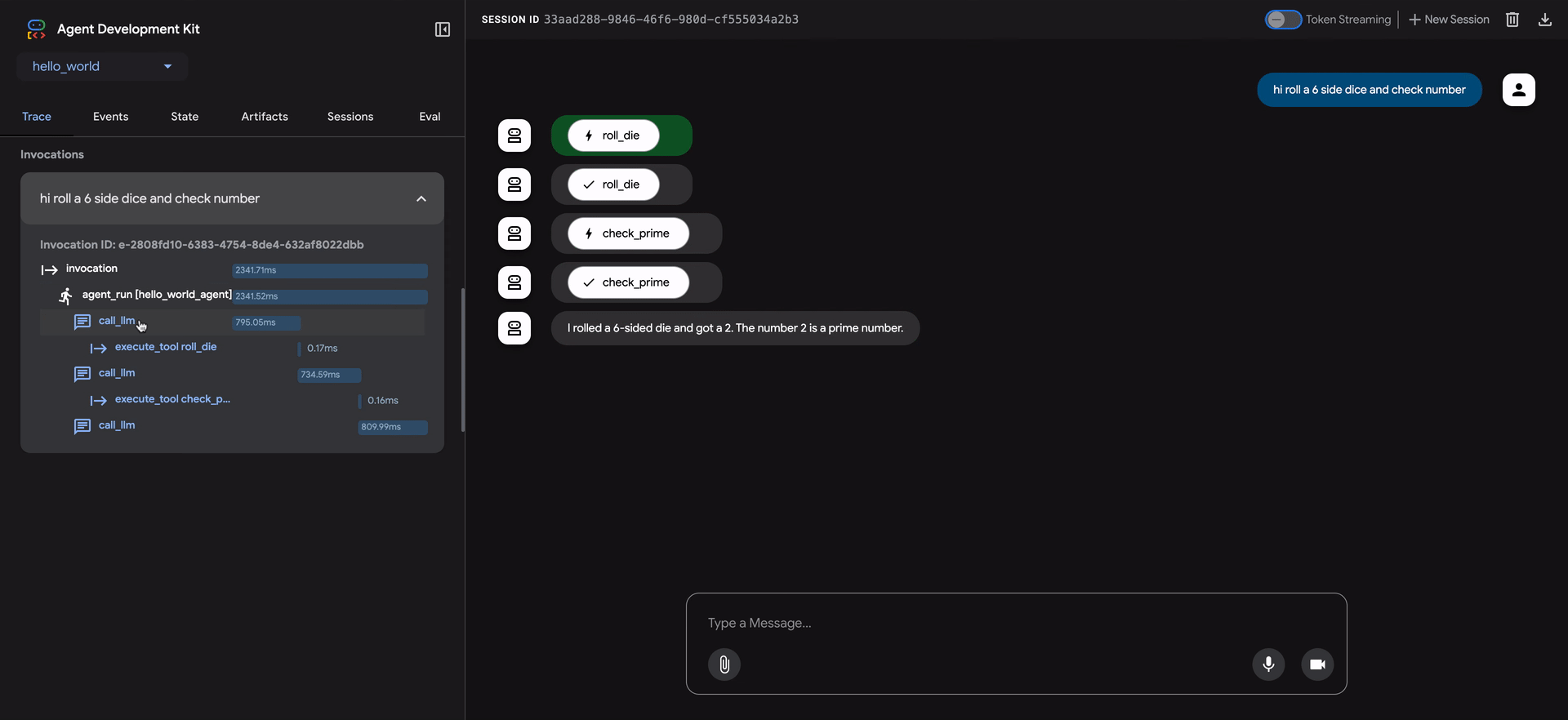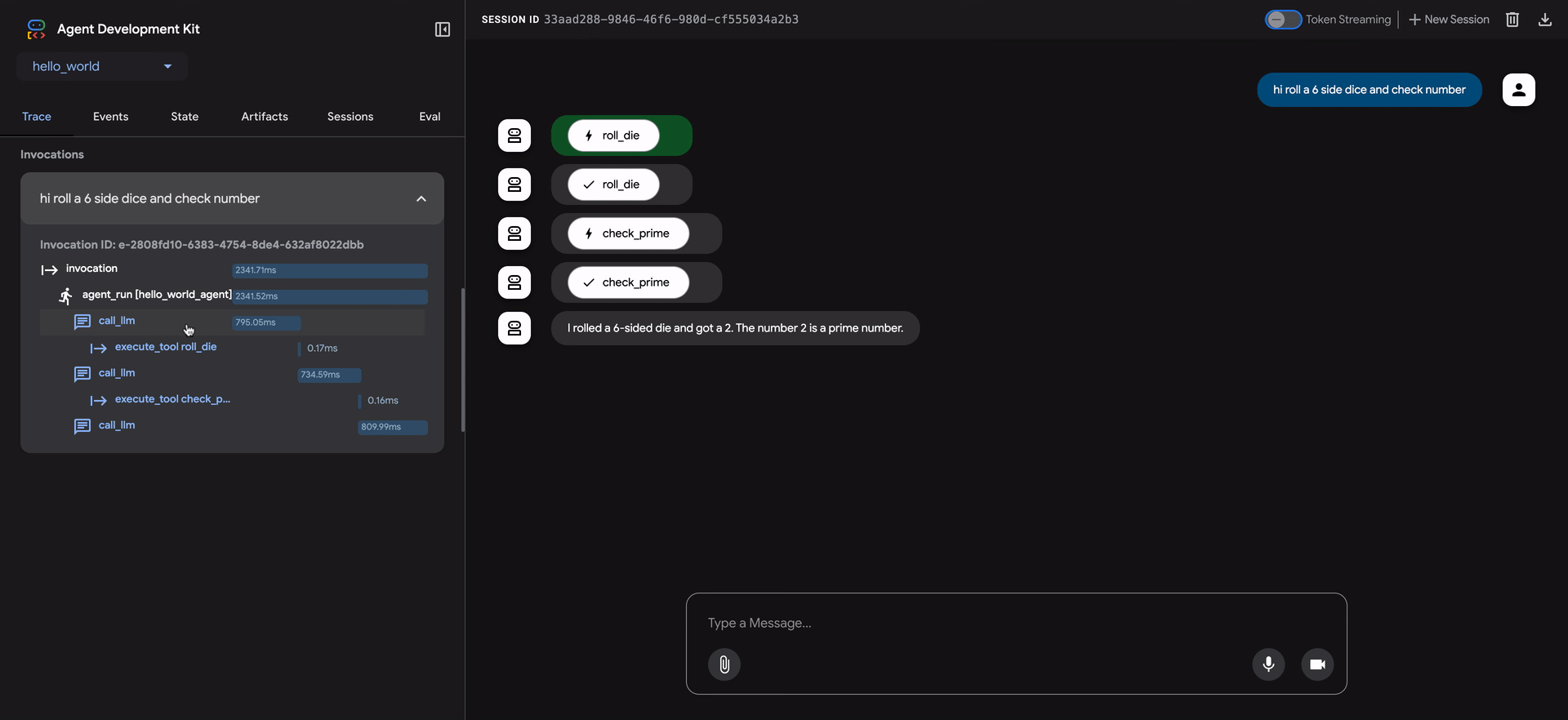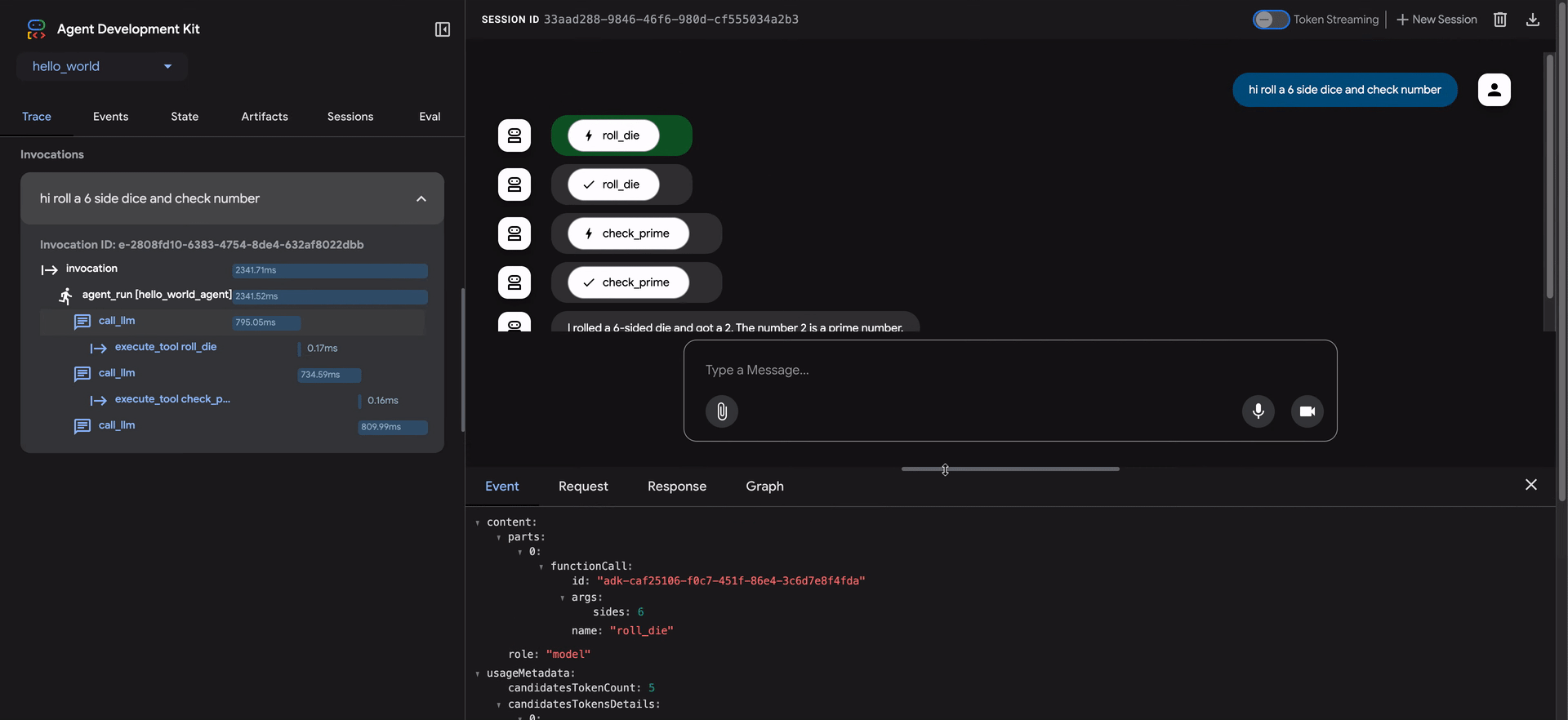
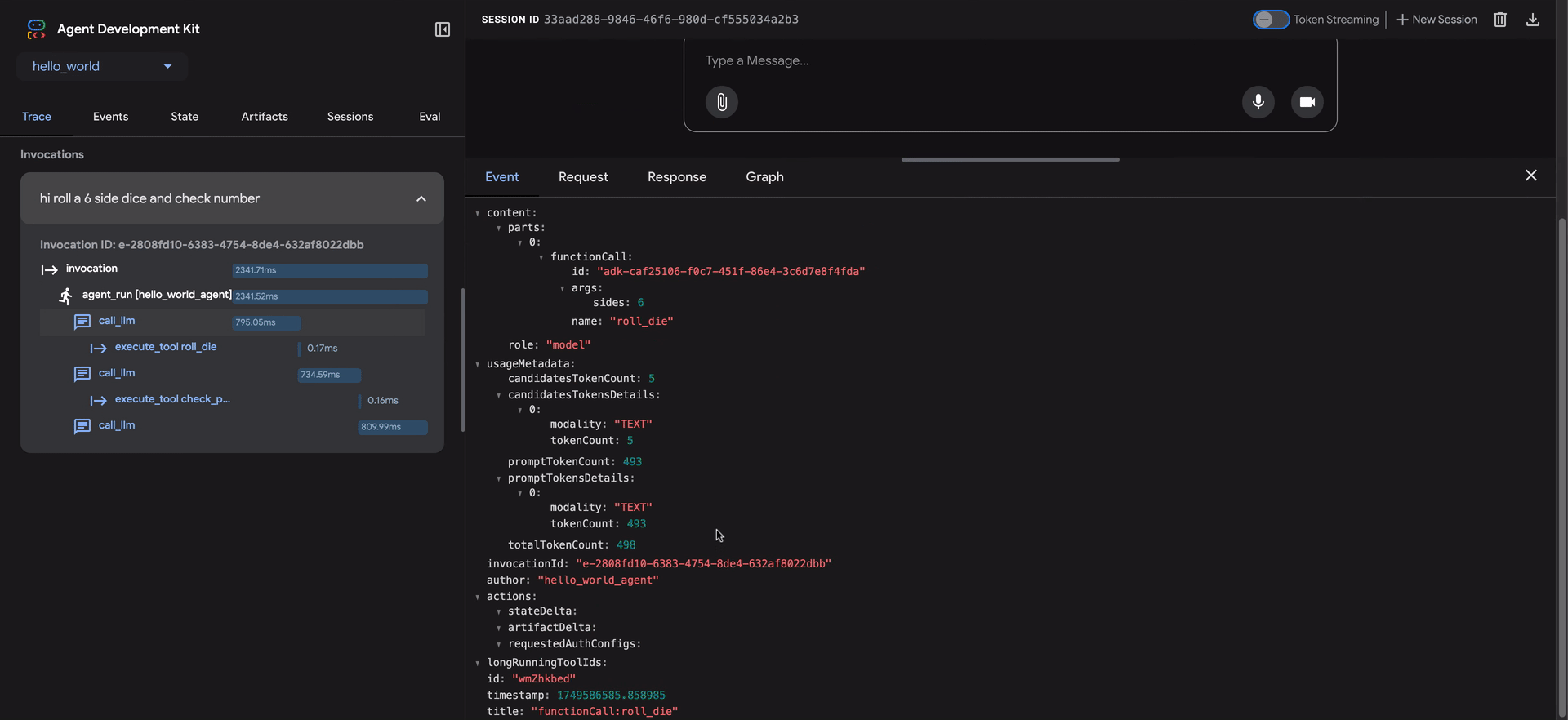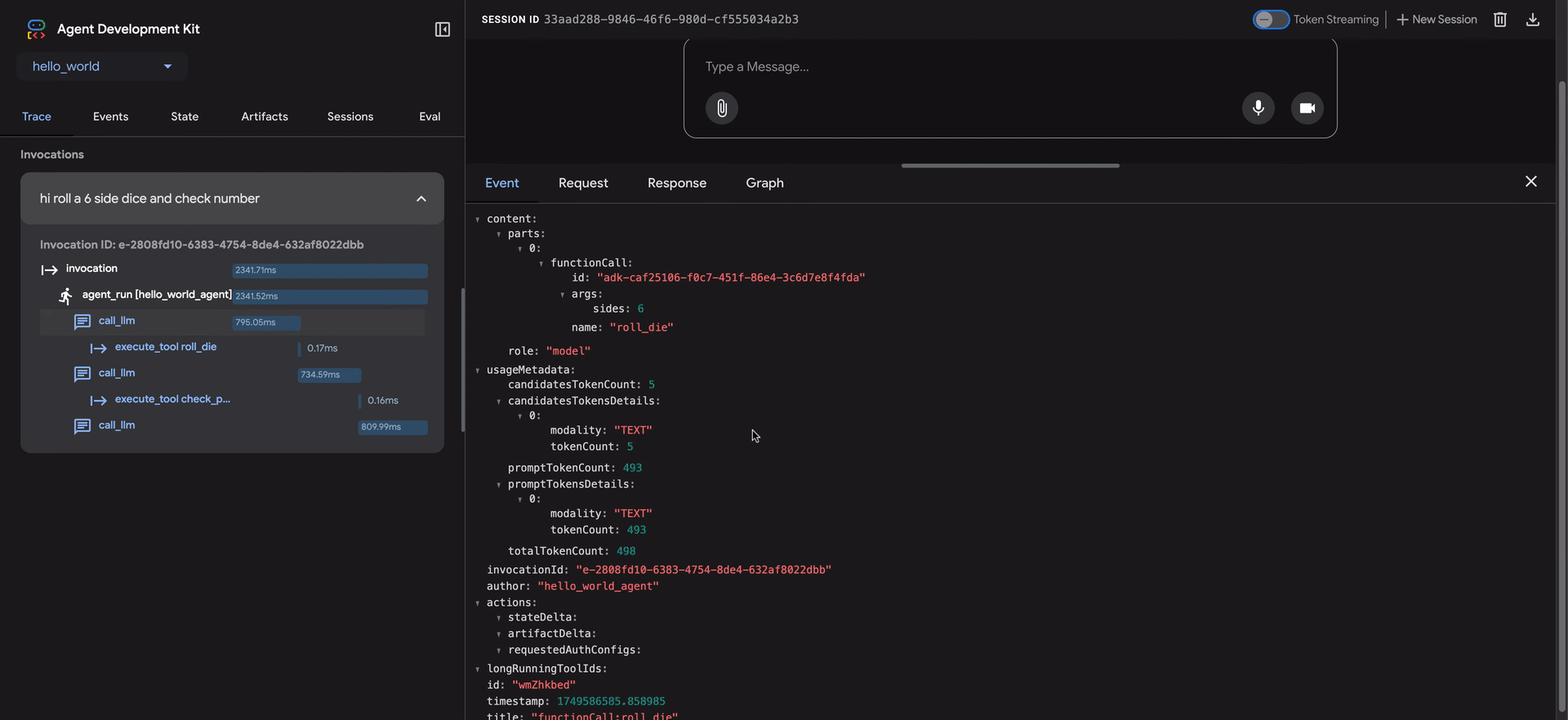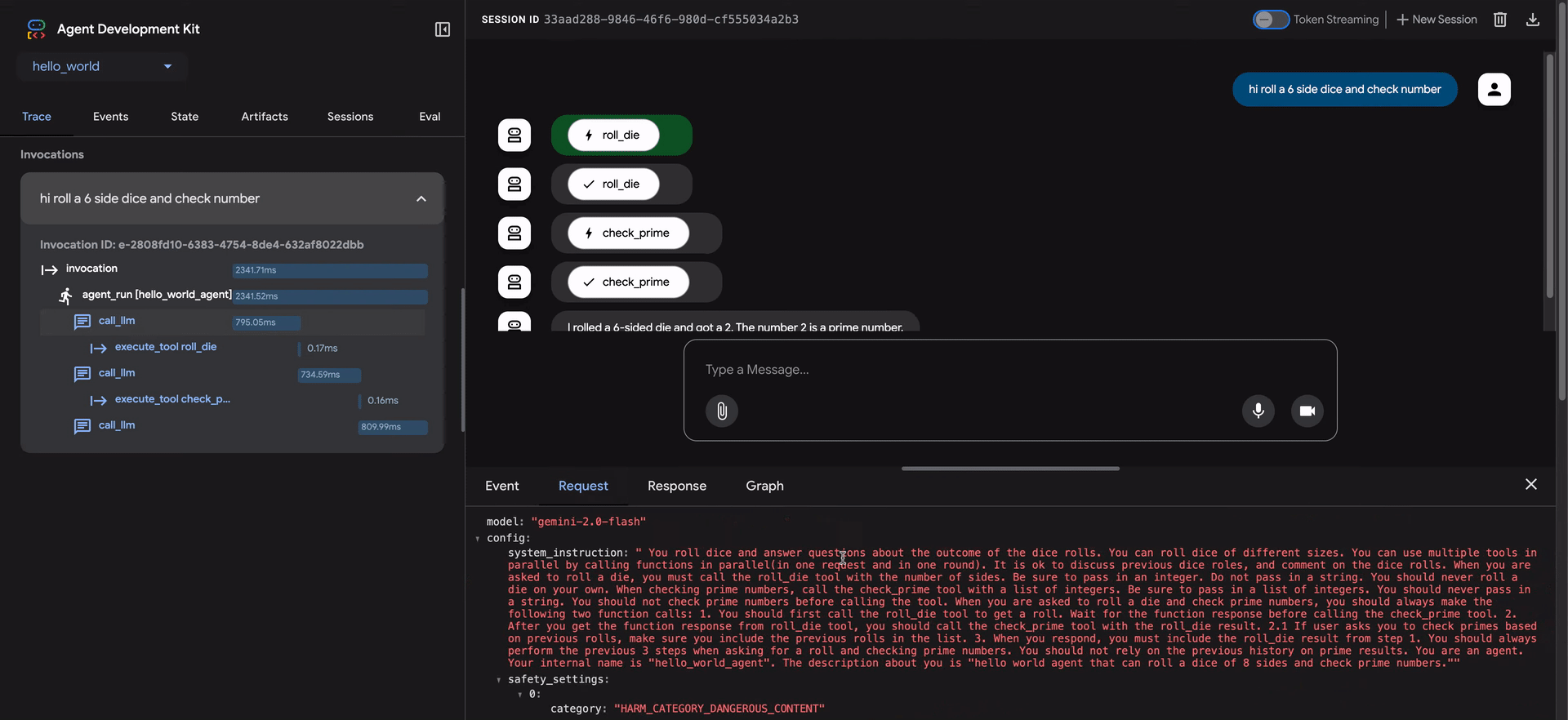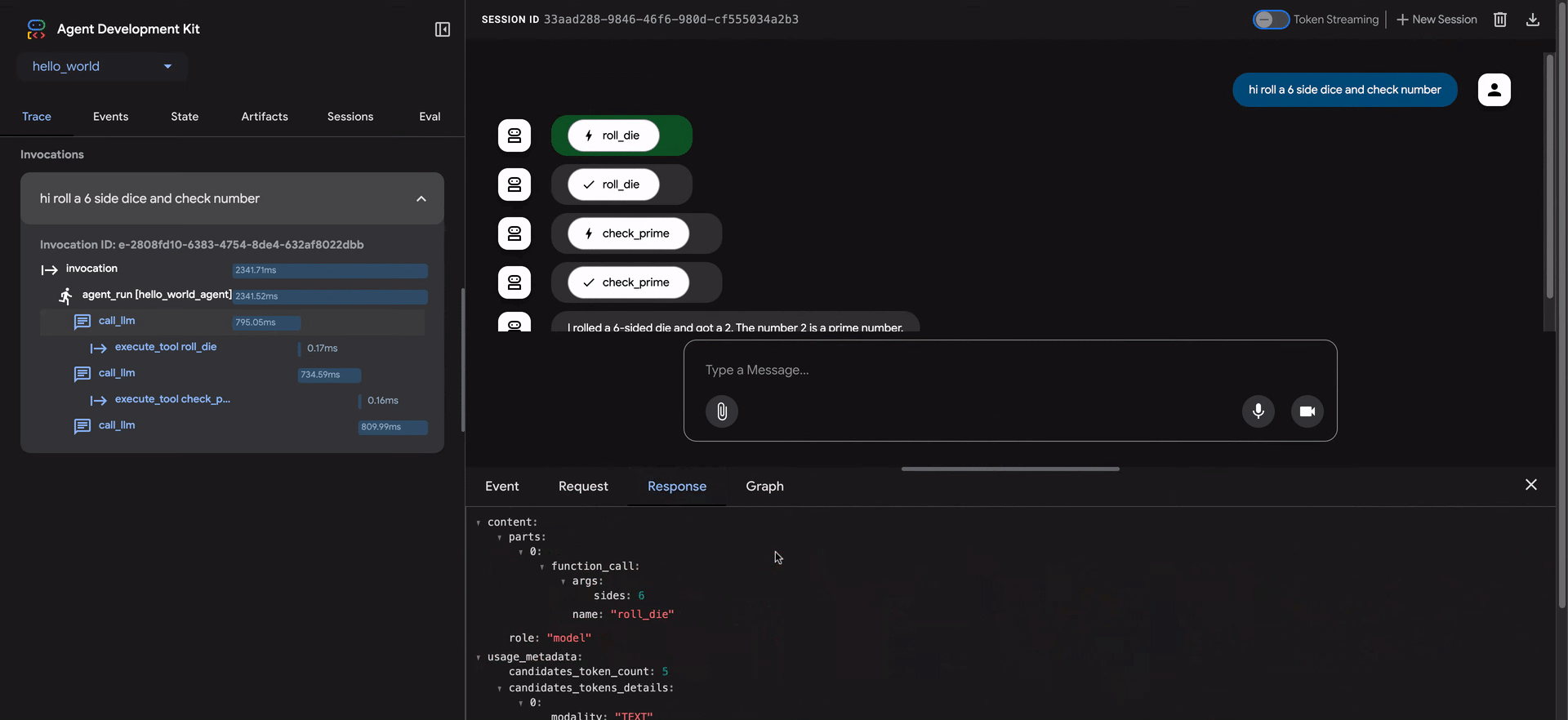
跟踪视图中的蓝色行表示该交互生成了事件。点击这些蓝色行将打开底部事件详细面板,提供对智能体执行流程的更深入见解。
2. pytest - 以编程方式运行测试¶
你还可以使用pytest作为集成测试的一部分运行测试文件。
示例命令¶
示例测试代码¶
以下是运行单个测试文件的pytest测试用例示例:
from google.adk.evaluation.agent_evaluator import AgentEvaluator
import pytest
@pytest.mark.asyncio
async def test_with_single_test_file():
"""通过会话文件测试智能体的基本能力。"""
await AgentEvaluator.evaluate(
agent_module="home_automation_agent",
eval_dataset_file_path_or_dir="tests/integration/fixture/home_automation_agent/simple_test.test.json",
)
这种方法允许你将智能体评估集成到 CI/CD 流水线或更大的测试套件中。如果你想为测试指定初始会话状态,可以通过在文件中存储会话详情并将其传递给AgentEvaluator.evaluate方法来实现。
3. adk eval - 通过 CLI 运行评估¶
你还可以通过命令行界面(CLI)运行评估集文件的评估。这运行与在 UI 上运行的相同评估,但有助于自动化,即你可以将此命令添加为常规构建生成和验证过程的一部分。
以下是命令:
adk eval \
<AGENT_MODULE_FILE_PATH> \
<EVAL_SET_FILE_PATH> \
[--config_file_path=<PATH_TO_TEST_JSON_CONFIG_FILE>] \
[--print_detailed_results]
例如:
adk eval \
samples_for_testing/hello_world \
samples_for_testing/hello_world/hello_world_eval_set_001.evalset.json
以下是每个命令行参数的详细信息:
AGENT_MODULE_FILE_PATH:包含名为"agent"的模块的init.py文件的路径。"agent"模块包含一个root_agent。EVAL_SET_FILE_PATH:评估文件的路径。你可以指定一个或多个评估集文件路径。对于每个文件,默认情况下将运行所有 evals。如果你只想从评估集运行特定的 evals,首先创建一个逗号分隔的 eval 名称列表,然后将其作为后缀添加到评估集文件名中,以冒号:分隔。- 例如:
sample_eval_set_file.json:eval_1,eval_2,eval_3
这将只运行sample_eval_set_file.json中的eval_1、eval_2和eval_3 CONFIG_FILE_PATH:配置文件的路径。PRINT_DETAILED_RESULTS:在控制台上打印详细结果。