第 1 部分:流式传输简介
Google 的 Agent Development Kit (ADK) 提供了一个生产就绪的框架,用于使用 Gemini 模型构建双向流式处理应用程序。本指南介绍了 ADK 的流式处理架构,该架构通过多模态通道(文本、音频、视频)实现用户与 AI 智能体之间的实时双向通信。
你将学到的内容:本部分涵盖双向流式处理的基础知识、底层 Live API 技术(Gemini Live API 和 Gemini Live API(Agent Platform))、ADK 架构组件(LiveRequestQueue、Runner、Agent)以及一个完整的 FastAPI 实现示例。你将了解 ADK 如何处理会话管理、工具编排和平台抽象——将数月的基础设施开发简化为声明式配置。
ADK Gemini Live API Toolkit 演示¶
ADK 双向流式处理演示¶
为了帮助你理解本指南中的概念,我们提供了一个可运行的演示应用程序,展示了 ADK 双向流式处理的实际应用。这个基于 FastAPI 的演示通过实用的真实架构实现了完整的流式处理生命周期。
演示仓库: adk-samples/python/agents/bidi-demo
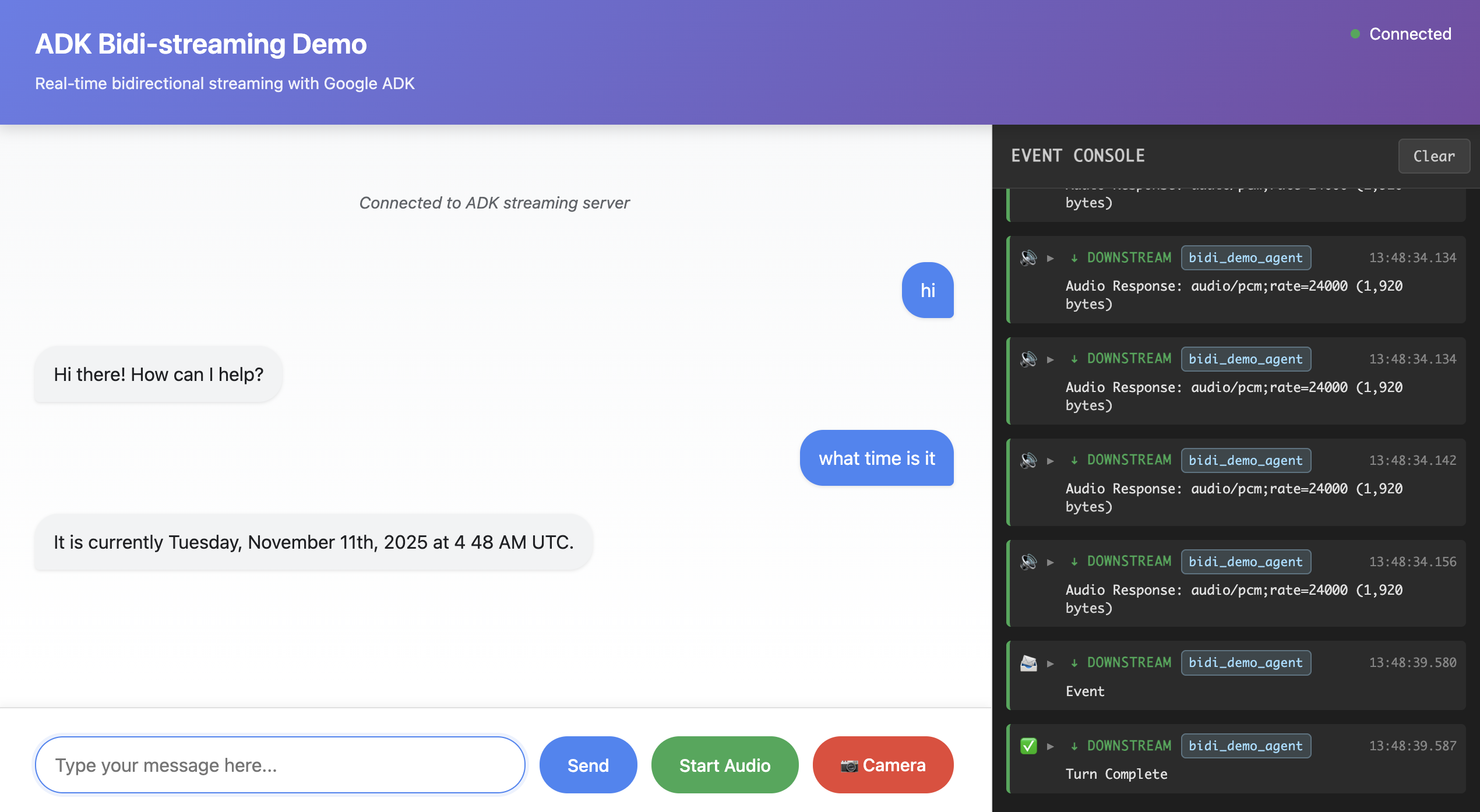
演示功能包括:
- WebSocket 通信:具有并发上行/下行任务的实时双向流式处理
- 多模态请求:带有自动转录的文本、音频和图像/视频输入
- 灵活响应:基于模型能力的文本或音频输出
- 交互式 UI:带有用于监控 Live API 事件的事件控制台的 Web 界面
- Google 搜索集成:配备工具调用能力的智能体
我们强烈建议在深入阅读本指南之前安装并运行此演示。动手实验将帮助你更深入地理解这些概念,并且演示代码将作为本指南所有部分的实用参考。
有关安装说明和使用详情,请参阅 演示 README。
1.1 什么是双向流式处理?¶
双向流式处理(Bidirectional streaming)代表了传统 AI 交互的根本性转变。它不再使用僵化的"询问 - 等待"模式,而是实现了实时的双向通信,人类和 AI 可以同时说话、听取和回应。这创造了自然的、类似人类的对话,具有即时响应和可以中断正在进行的交互的革命性能力。
想象一下发送电子邮件和打电话的区别。传统的 AI 交互就像电子邮件——你发送一条完整的消息,等待完整的回复,然后发送另一条完整的消息。双向流式处理就像电话交谈——流畅、自然,能够实时打断、澄清和回应。
关键特征¶
这些特征将双向流式处理与传统 AI 交互区分开来,使其在创建引人入胜的用户体验方面具有独特的强大功能:
-
双向通信:无需等待完整响应的连续数据交换。用户可以用新输入打断智能体的回应,从而创建自然的对话流。AI 在检测到用户说完话后(通过自动语音活动检测或显式活动信号)进行响应。
-
响应式中断:这可能是自然用户体验最重要的功能——用户可以在智能体回应中途用新输入打断它,就像在人类对话中一样。如果 AI 正在解释量子物理学,而你突然问"等等,什么是电子?",AI 会立即停止并解决你的问题。
-
最适合多模态:双向流式处理在多模态交互方面表现出色,因为它可以通个单一连接同时处理不同的输入类型。用户可以在展示文档时说话,在语音通话期间输入后续问题,或在不丢失上下文的情况下无缝切换通信模式。这种统一的方法消除了管理每种模态的单独通道的复杂性。
sequenceDiagram
participant Client as 用户
participant Agent as 智能体
Client->>Agent: "你好!"
Client->>Agent: "解释一下日本的历史"
Agent->>Client: "你好!"
Agent->>Client: "当然!日本的历史是... (部分内容)"
Client->>Agent: "啊,等等。"
Agent->>Client: "好的,有什么可以帮你的? [interrupted: true]"与其他流式处理类型的区别¶
了解双向流式处理与其他方法的区别对于理解其独特价值至关重要。流式处理领域包括几种不同的模式,每种模式服务于不同的用例:
流式处理类型比较
双向流式处理与其他流式处理方法有根本区别:
-
服务端流式处理:从服务器到客户端的单向数据流。就像观看实时视频流——你接收连续数据,但无法实时与其交互。对仪表板或实时信息流有用,但不适合对话。
-
令牌级流式处理:无中断的顺序文本令牌传递。AI 逐词生成响应,但你必须等待完成后才能发送新输入。就像实时观看某人打字一样——你看到它在形成,但无法打断。
-
双向流式处理:具有中断支持的全双向通信。真正的对话式 AI,双方可以同时说话、听取和回应。这就是实现自然对话的原因,你可以在对话中途打断、澄清或改变话题。
真实世界应用¶
双向流式处理通过使智能体能够以类似人类的响应能力和智能进行操作,彻底改变了智能体 AI 应用程序。这些应用程序展示了流式处理如何将静态 AI 交互转变为动态的、智能体驱动的体验,这种体验感觉真正智能且主动。
在 购物者礼宾演示 的视频中,多模态双向流式处理功能通过实现更快、更直观的购物体验,显著改善了电子商务的用户体验。对话理解和快速、并行搜索的结合最终实现了虚拟试穿等高级功能,增强了买家信心并减少了在线购物的摩擦。
此外,双向流式处理还有许多可能的实际应用:
客户服务和联络中心¶
这是最直接的应用。该技术可以创建远超传统聊天机器人的复杂虚拟智能体。
- 用例:客户致电零售公司的支持热线,咨询有缺陷的产品。
- 多模态(视频):客户可以说,“我的咖啡机底部漏水,让我给你看看。”然后他们可以使用手机摄像头流式传输问题的实时视频。AI 智能体可以使用其视觉能力来识别型号和具体的故障点。
- 实时交互与中断:如果智能体说,“好的,我正在为你处理 X 型咖啡机的退货,”客户可以打断说,“不,等等,是 Y Pro 型,”智能体可以立即纠正其过程,而无需重新开始对话。
电子商务和个性化购物¶
智能体可以充当实时、互动的私人购物者,增强在线零售体验。
- 用例:用户正在浏览时尚网站并想要造型建议。
- 多模态(语音和图像):用户可以将一件衣服举到网络摄像头前问,“你能帮我找一双配这条裤子的鞋子吗?”智能体分析裤子的颜色和款式。
- 实时交互:对话可以是流畅的来回交流:“给我看一些更休闲的。”...“好的,这双运动鞋怎么样?”...“完美,把这双蓝色的 10 码加到我的购物车。”
现场服务和技术援助¶
在现场工作的技术人员可以使用免提、声控助手获得实时帮助。
- 用例:暖通空调技术人员正在现场试图诊断一台复杂的商用空调机组。
- 多模态(视频和语音):戴着智能眼镜或使用手机的技术人员可以将他们的视角流式传输给 AI 智能体。他们可以问,“我听到这台压缩机发出奇怪的声音。你能识别它并调出该型号的诊断流程图吗?”
- 实时交互:智能体可以一步步指导技术人员,技术人员可以随时提出澄清问题或打断,而无需停下手中的工作。
医疗保健和远程医疗¶
智能体可以作为患者接收、分诊和基本咨询的第一接触点。
- 用例:患者使用提供商的应用程序进行皮肤状况的初步咨询。
- 多模态(视频/图像):患者可以安全地分享皮疹的实时视频或高分辨率图像。AI 可以进行初步分析并提出澄清问题。
金融服务和财富管理¶
智能体可以为客户提供一种安全、互动且数据丰富的方式来管理他们的财务。
- 用例:客户想要审查他们的投资组合并讨论市场趋势。
- 多模态(屏幕共享):智能体可以共享其屏幕以显示图表、图形和投资组合表现数据。客户也可以共享他们的屏幕指向特定的新闻文章并问,“这一事件对我的科技股有什么潜在影响?”
- 实时交互:通过访问他们的账户数据分析客户当前的投资组合配置。模拟潜在交易对投资组合风险状况的影响。
1.2 Gemini Live API and Gemini Live API (Agent Platform)¶
ADK Gemini Live API Toolkit 的能力由 Live API 技术支持,可通过两个平台获得:Gemini Live API(通过 Google AI Studio)和 Gemini Live API (Agent Platform)(通过 Google Cloud)。两者都提供与 Gemini 模型的实时低延迟流式对话,但服务于不同的开发和部署需求。
在本指南中,我们将 "Live API" 统称这两个平台,仅在讨论平台特定功能或差异时指定"Gemini Live API"或"Gemini Live API (Agent Platform)"。
什么是 Live API?¶
Live API 是 Google 的实时对话 AI 技术,支持与 Gemini 模型进行低延迟双向流式处理。与传统的请求 - 响应 API 不同,Live API 建立持久的 WebSocket 连接,支持:
核心能力:
- 多模态流式处理:实时处理连续的音频、视频和文本流
- 语音活动检测 (VAD):自动检测用户何时说完话,无需显式信号即可实现自然轮流对话。AI 知道何时开始响应以及何时等待更多输入
- 即时响应:以极低的延迟提供类似人类的语音或文本响应
- 智能中断:允许用户在 AI 回应中途打断,就像人类对话一样
- 音频转录:实时转录用户输入和模型输出,无需单独的转录服务即可实现辅助功能和对话记录
- 会话管理:长对话可以通过会话恢复跨越多个连接,API 在重新连接时保留完整的对话历史记录和上下文
- 工具集成:函数调用在流式处理模式下无缝工作,工具在后台执行而对话继续进行
原生音频模型特性:
- 主动音频:模型可以根据上下文感知发起响应,创建更自然的交互,AI 主动提供帮助或澄清(仅限原生音频模型)
- 情感对话:高级模型理解语调和情感背景,调整响应以匹配对话情绪和用户情绪(仅限原生音频模型)
了解更多
有关原生音频模型和这些特性的详细信息,请参阅 第 5 部分:音频和视频 - 主动性和情感对话。
技术规格:
- 音频输入:16kHz 的 16 位 PCM(单声道)
- 音频输出:24kHz 的 16 位 PCM(原生音频模型)
- 视频输入:每秒 1 帧,推荐 768x768 分辨率
- 上下文窗口:因模型而异(Live API 模型通常为 32k-128k 令牌)。有关具体限制,请参阅 Gemini 模型。
- 语言:支持 24 种以上语言,具有自动检测功能
Gemini Live API 与 Gemini Live API(Agent Platform)的对比¶
两个 API 都提供相同的核心 Live API 技术,但在部署平台、身份验证和企业功能方面有所不同:
| 方面 | Gemini Live API | Gemini Live API (Agent Platform) |
|---|---|---|
| 访问 | Google AI Studio | Google Cloud |
| 身份验证 | API 密钥 (GOOGLE_API_KEY) |
Google Cloud 凭据 (GOOGLE_CLOUD_PROJECT, GOOGLE_CLOUD_LOCATION) |
| 最适合 | 快速原型设计、开发、实验 | 生产部署、企业级应用程序 |
| 会话时长 | 纯音频:15 分钟 音频 + 视频:2 分钟 使用上下文窗口压缩:无限制 |
两者:10 分钟 使用上下文窗口压缩:无限制 |
| 并发会话 | 基于层级的配额(见 API 配额) | 每个项目最多 1,000 个(可通过配额请求配置) |
| 企业功能 | 基础 | 高级监控、日志记录、SLA、会话恢复(24 小时) |
| 设置复杂性 | 极小(仅 API 密钥) | 需要 Google Cloud 项目设置 |
| API 版本 | v1beta |
v1beta1 |
| API 端点 | generativelanguage.googleapis.com |
{location}-aiplatform.googleapis.com |
| 计费 | 通过 API 密钥跟踪使用情况 | Google Cloud 项目计费 |
Live API 参考说明
并发会话限制:基于配额,可能因账户层级或配置而异。请在 Google AI Studio 或 Google Cloud Console 中查看当前配额。
官方文档:Gemini Live API 指南 | Gemini Live API (Agent Platform) 概览
1.3 ADK Gemini Live API Toolkit:用于构建实时智能体应用程序¶
从头开始构建实时智能体应用程序面临着巨大的工程挑战。虽然 Live API 提供了底层的流式处理技术,但将其集成到生产应用程序中需要解决复杂的问题:管理 WebSocket 连接和重连逻辑、编排工具执行和响应处理、跨会话持久化对话状态、协调多模态输入的并发数据流,以及处理开发和生产环境之间的平台差异。
ADK 将这些挑战转化为简单、声明式的 API。开发人员无需花费数月时间构建用于会话管理、工具编排和状态持久化的基础设施,而是可以专注于定义智能体行为和创建用户体验。本节探讨 ADK 自动处理的内容以及为什么它是构建生产就绪流式处理应用程序的推荐路径。
原生 Live API 与 ADK Gemini Live API Toolkit 对比:
| 特性 | 原生 Live API (google-genai SDK) |
ADK Gemini Live API Toolkit (adk-python 和 adk-java SDK) |
|---|---|---|
| 智能体框架 | ❌ 不可用 | ✅ 单智能体、带子智能体的多智能体、顺序工作流智能体、工具生态系统、部署就绪、评估、安全等(参见 ADK 智能体文档) |
| 工具执行 | ❌ 手动工具执行和响应处理 | ✅ 自动工具执行(参见第 3 部分:工具调用事件) |
| 连接管理 | ❌ 手动重连和会话恢复 | ✅ 自动重连和会话恢复(参见第 4 部分:Live API 会话恢复) |
| 事件模型 | ❌ 自定义事件结构和序列化 | ✅ 带元数据的统一事件模型(参见第 3 部分:事件处理) |
| 异步事件处理框架 | ❌ 手动异步协调和流处理 | ✅ LiveRequestQueue、run_live() 异步生成器、自动双向流协调(参见第 2 部分和第 3 部分) |
| 应用级会话持久化 | ❌ 手动实现 | ✅ SQL 数据库(PostgreSQL、MySQL、SQLite)、Agent Platform、内存中(参见ADK 会话文档) |
平台灵活性¶
ADK 最强大的功能之一是其透明地支持 Gemini Live API 和 Gemini Live API (Agent Platform)。这种平台灵活性实现了从开发到生产的无缝工作流:使用免费 API 密钥在本地使用 Gemini API 进行开发,然后使用企业级 Google Cloud 基础设施部署到生产环境中的 Agent Platform——无需更改应用程序代码,仅需环境配置。
平台选择如何工作¶
ADK 使用 GOOGLE_GENAI_USE_VERTEXAI 环境变量来确定使用哪个 Live API 平台:
GOOGLE_GENAI_USE_VERTEXAI=FALSE(或未设置):通过 Google AI Studio 使用 Gemini Live APIGOOGLE_GENAI_USE_VERTEXAI=TRUE:通过 Google Cloud 使用 Gemini Live API(Agent Platform)
当 ADK 创建 LLM 连接时,底层 google-genai SDK 会读取此环境变量。切换平台时无需更改代码——只需更改环境配置。
开发阶段:Gemini Live API (Google AI Studio)¶
优势:
- 使用 Google AI Studio 的免费 API 密钥进行快速原型设计
- 无需 Google Cloud 设置
- 即时实验流式处理功能
- 开发期间零基础设施成本
生产阶段:Gemini Live API(Agent Platform)¶
# .env.production
GOOGLE_GENAI_USE_VERTEXAI=TRUE
GOOGLE_CLOUD_PROJECT=your_project_id
GOOGLE_CLOUD_LOCATION=us-central1
优势:
- 通过 Google Cloud 提供的企业级基础设施
- 高级监控、日志记录和成本控制
- 与现有 Google Cloud 服务集成
- 生产 SLA 和支持
- 无需更改代码 - 仅需环境配置
通过处理会话管理、工具编排、状态持久化和平台差异的复杂性,ADK 让你专注于构建智能智能体体验,而不是与流式处理基础设施搏斗。相同的代码在开发和生产环境中无缝工作,让你在没有实现负担的情况下获得双向流式处理的全部能力。
1.4 ADK Gemini Live API Toolkit 架构概览¶
现在你了解了 Live API 技术以及 ADK 为何增加价值,让我们探索 ADK 实际上是如何工作的。本节映射了从你的应用程序通过 ADK 流水线到 Live API 并返回的完整数据流,展示了哪些组件处理哪些职责。
你将看到像 LiveRequestQueue、Runner 和 Agent 这样的关键组件如何编排流式对话,而无需你管理 WebSocket 连接、协调异步流或处理特定于平台的 API 差异。
高级架构¶
graph TB
subgraph "应用程序"
subgraph "客户端"
C1["Web / 移动端"]
end
subgraph "传输层"
T1["WebSocket / SSE (例如 FastAPI)"]
end
end
subgraph "ADK"
subgraph "ADK Gemini Live API Toolkit"
L1[LiveRequestQueue]
L2[Runner]
L3[Agent]
L4[LLM Flow]
end
subgraph "LLM Integration"
G1[GeminiLlmConnection]
G2[Gemini Live API / Gemini Live API on Agent Platform]
end
end| 开发者提供: | ADK 提供: | Live API 提供: |
|---|---|---|
| Web / Mobile: 用户交互的前端应用程序,处理 UI/UX、用户输入捕获和响应显示 WebSocket / SSE 服务器:管理客户端连接、处理流式协议并在客户端与 ADK 之间路由消息的实时通信服务器(例如 FastAPI) Agent:根据应用程序需求定制的自定义 AI 智能体定义,包含特定的指令、工具和行为 |
LiveRequestQueue:缓冲和排序传入用户消息(文本内容、音频 blob、控制信号)的消息队列,供智能体有序处理 Runner:编排智能体会话、管理对话状态并提供 run_live() 流式接口的执行引擎RunConfig:流式行为、模态和高级功能的配置 内部组件(自动管理,开发者不直接使用):LLM Flow 用于处理流水线,GeminiLlmConnection 用于协议转换 |
Gemini Live API(通过 Google AI Studio)和 Gemini Live API (Agent Platform)(通过 Google Cloud):Google 的实时语言模型服务,处理流式输入,生成响应,处理中断,支持多模态内容(文本、音频、视频),并提供函数调用和上下文理解等高级 AI 能力 |
此架构展示了 ADK 清晰的关注点分离:你的应用程序处理用户交互和传输协议,ADK 管理流式编排和状态,而 Live API 提供 AI 智能。通过抽象 LLM 端流式连接管理、事件循环和协议转换的复杂性,ADK 使你能够专注于构建智能体行为和用户体验,而不是流式基础设施。
1.5 ADK Gemini Live API Toolkit 应用程序生命周期¶
ADK Gemini Live API Toolkit 将 Live API 会话集成到 ADK 框架的任务生命周期中。这种集成创建了一个四阶段生命周期,将 ADK 的智能体管理与 Live API 的实时流式处理能力相结合:
- 第 1 阶段:应用程序初始化(启动时执行一次)
-
ADK 应用程序初始化
- 创建 Agent:用于与用户交互、利用外部工具以及与其他智能体协调。
- 创建 SessionService:用于获取或创建 ADK
Session - 创建 Runner:为 Agent 提供运行时
-
第 2 阶段:会话初始化(每个用户会话一次)
- ADK
Session初始化:- 使用
SessionService获取或创建 ADKSession
- 使用
-
ADK Gemini Live API Toolkit 初始化:
- 创建用于配置 ADK Gemini Live API Toolkit 的 RunConfig
- 创建用于向
Agent发送用户消息的 LiveRequestQueue - 启动 run_live() 事件循环
-
阶段 3:使用
run_live()事件循环进行双向流式处理(每个用户会话一次或多次) - 上行:用户使用
LiveRequestQueue向智能体发送消息 -
下行:智能体使用
Event向用户响应 -
阶段 4:终止 Live API 会话(每个用户会话一次或多次)
LiveRequestQueue.close()
生命周期流程概览:
graph TD
subgraph Phase1["第 1 阶段:应用程序初始化<br/>启动时一次"]
Init["初始化 Agent, Runner, SessionService"]
end
subgraph Phase2["第 2 阶段:会话初始化<br/>每个用户连接"]
Session["获取/创建 Session"]
Config["创建 RunConfig & Queue"]
end
subgraph Phase3["第 3 阶段:双向流式处理<br/>活跃通信"]
Loop["run_live() 事件循环"]
end
subgraph Phase4["第 4 阶段:终止<br/>关闭会话"]
Close["Queue.close()"]
end
Phase1 -->|"新连接"| Phase2
Phase2 --> Phase3
Phase3 --> Phase4此流程图显示了高级生命周期阶段及其连接方式。下面的详细序列图说明了每个阶段中的具体组件和交互。
sequenceDiagram
participant Client
participant App as Application Server
participant Queue as LiveRequestQueue
participant Runner
participant Agent
participant API as Live API
rect rgb(230, 240, 255)
Note over App: "第 1 阶段:应用程序初始化(启动时一次)"
App->>Agent: "1. 创建 Agent(model, tools, instruction)"
App->>App: "2. 创建 SessionService()"
App->>Runner: "3. 创建 Runner(app_name, agent, session_service)"
end
rect rgb(240, 255, 240)
Note over Client,API: "第 2 阶段:会话初始化(每次用户连接时)"
Client->>App: "1. WebSocket connect(user_id, session_id)"
App->>App: "2. get_or_create_session(app_name, user_id, session_id)"
App->>App: "3. 创建 RunConfig(streaming_mode, modalities)"
App->>Queue: "4. 创建 LiveRequestQueue()"
App->>Runner: "5. 启动 run_live(user_id, session_id, queue, config)"
Runner->>API: "连接到 Live API 会话"
end
rect rgb(255, 250, 240)
Note over Client,API: "第 3 阶段:使用 run_live() 事件循环进行双向流式处理"
par "上行:用户通过 LiveRequestQueue 发送消息"
Client->>App: "用户消息 (文本/音频/视频)"
App->>Queue: "send_content() / send_realtime()"
Queue->>Runner: "缓冲请求"
Runner->>Agent: "处理请求"
Agent->>API: "流式传输到 Live API"
and "下行:智能体通过事件响应"
API->>Agent: "流式传输响应"
Agent->>Runner: "处理响应"
Runner->>App: "yield Event (文本/音频/工具/轮次)"
App->>Client: "通过 WebSocket 转发事件"
end
Note over Client,API: "(事件循环持续直到关闭信号)"
end
rect rgb(255, 240, 240)
Note over Client,API: "第 4 阶段:终止 Live API 会话"
Client->>App: "WebSocket 断开连接"
App->>Queue: "close()"
Queue->>Runner: "关闭信号"
Runner->>API: "断开与 Live API 的连接"
Runner->>App: "run_live() 退出"
end在接下来的部分中,你将看到每个阶段的详细信息,展示何时创建每个组件以及它们如何协同工作。理解这种生命周期模式对于构建能够有效处理多个并发会话的健壮流式处理应用程序至关重要。
第 1 阶段:应用程序初始化¶
这些组件在应用程序启动时创建一次,并在所有流式处理会话中共享。它们定义了智能体的能力,管理对话历史记录,并编排流式处理执行。
定义你的智能体¶
Agent 是流式处理应用程序的核心——它定义了 AI 能做什么,应该如何表现,以及哪个 AI 模型为其提供动力。你需要为智能体配置特定的模型、它可以使用的工具(如 Google 搜索或自定义 API)以及塑造其个性和行为的指令。
"""ADK Gemini Live API Toolkit 演示的 Google 搜索智能体定义。"""
import os
from google.adk.agents import Agent
from google.adk.tools import google_search
# Default models for Live API with native audio support:
# - Gemini Live API: gemini-2.5-flash-native-audio-preview-12-2025
# - Gemini Live API (Agent Platform): gemini-live-2.5-flash-native-audio
agent = Agent(
name="google_search_agent",
model=os.getenv("DEMO_AGENT_MODEL", "gemini-2.5-flash-native-audio-preview-12-2025"),
tools=[google_search],
instruction="你是一个可以搜索网络的有用助手。"
)
智能体实例是无状态且可重用的——你创建一次,可用于所有流式处理会话。智能体配置在 ADK 智能体文档 中介绍。
模型可用性
有关最新支持的模型及其功能,请参阅 第 5 部分:理解音频模型架构。
Agent 与 LlmAgent
Agent 是 LlmAgent 的推荐简写(两者都从 google.adk.agents 导入)。它们是相同的 - 使用你喜欢的任何一个。本指南为简洁起见使用 Agent,但你可能会在其他 ADK 文档和示例中看到 LlmAgent。
定义你的 SessionService¶
ADK Session 管理跨流式处理会话的对话状态和历史记录。它存储和检索会话数据,支持对话恢复和上下文持久化等功能。
要创建 Session,或为指定的 session_id 获取现有会话,每个 ADK 应用程序都需要有一个 SessionService。出于开发目的,ADK 提供了一个简单的 InMemorySessionService,它会在应用程序关闭时丢失 Session 状态。
from google.adk.sessions import InMemorySessionService
# Define your session service
session_service = InMemorySessionService()
对于生产应用程序,请根据你的基础设施选择持久化会话服务:
使用 DatabaseSessionService 如果:
- 你需要使用 SQLite、PostgreSQL 或 MySQL 进行持久化存储
- 你正在构建单服务器应用 (SQLite) 或多服务器部署 (PostgreSQL/MySQL)
- 你希望完全控制数据存储和备份
-
示例:
- SQLite:
DatabaseSessionService(db_url="sqlite+aiosqlite:///./sessions.db") - PostgreSQL:
DatabaseSessionService(db_url="postgresql://user:pass@host/db")
Note
对于 SQLite,请使用
sqlite+aiosqlite(例如sqlite+aiosqlite:///./sessions.db) 而不是sqlite,因为DatabaseSessionService需要异步数据库驱动程序。 - SQLite:
-
你已经在使用 Google Cloud Platform
- 你需要具有内置可扩展性的托管存储
- 你需要与 Agent Platform 功能紧密集成
- 示例:
VertexAiSessionService(project="my-project")
两者都提供会话持久化功能——根据你的基础设施和规模需求进行选择。使用持久化会话服务,即使在应用程序关闭后,Session 的状态也会被保留。有关更多详细信息,请参阅 ADK 会话管理文档。
两者都提供会话持久化功能——根据你的基础设施和规模需求进行选择。使用持久化会话服务,即使在应用程序关闭后,Session 的状态也会被保留。有关更多详细信息,请参阅 ADK 会话管理文档。
Runner 为 Agent 提供运行时。它管理对话流程,协调工具执行,处理事件,并与会话存储集成。你在应用程序启动时创建一个运行器实例,并将其重用于所有流式处理会话。
from google.adk.runners import Runner
APP_NAME = "bidi-demo"
# Define your runner
runner = Runner(
app_name=APP_NAME,
agent=agent,
session_service=session_service
)
app_name 参数是必需的,用于在会话存储中标识你的应用程序。你的应用程序的所有会话都在此名称下组织。
第 2 阶段:会话初始化¶
获取或创建会话¶
ADK Session(会话)提供了 ADK Gemini Live API Toolkit 应用程序的"对话线程"。就像你不会从头开始发送每条短信一样,智能体需要有关正在进行的交互的上下文。Session 是专门为跟踪和管理这些独立对话线程而设计的 ADK 对象。
ADK Session 与 Live API 会话¶
ADK Session(由 SessionService 管理)提供跨多个双向流式处理会话(可持续数小时、数天甚至数月)的持久对话存储,而 Live API 会话(由 Live API 后端管理)是仅在单个双向流式处理事件循环期间存在的瞬态流式处理上下文(通常持续几分钟或几小时),我们稍后将讨论。当循环开始时,ADK 使用来自 ADK Session 的历史记录初始化 Live API 会话,然后在发生新事件时更新 ADK Session。
了解更多
有关带有序列图的详细比较,请参阅 第 4 部分:ADK Session 与 Live API 会话。
会话标识符由应用程序定义¶
会话由三个参数标识:app_name、user_id 和 session_id。这种三级层次结构支持多租户应用程序,其中每个用户可以有多个并发会话。
user_id 和 session_id 都是你根据应用程序需求定义的任意字符串标识符。ADK 不会对 session_id 执行除 .strip() 之外的格式验证——你可以使用任何对你的应用程序有意义的字符串值:
user_id示例:用户 UUID ("550e8400-e29b-41d4-a716-446655440000")、电子邮件地址 ("alice@example.com")、数据库 ID ("user_12345") 或简单标识符 ("demo-user")session_id示例:自定义会话令牌、UUID、基于时间戳的 ID ("session_2025-01-27_143022") 或简单标识符 ("demo-session")
自动生成:如果你向 create_session() 传递 session_id=None 或空字符串,ADK 会自动为你生成一个 UUID(例如,"550e8400-e29b-41d4-a716-446655440000")。
组织层次结构:这些标识符在三级结构中组织会话:
这种设计支持如下场景:
- 多租户应用程序,其中不同用户拥有隔离的对话空间
- 单个用户拥有多个并发聊天线程(例如,不同的话题)
- 每个设备或每个浏览器的会话隔离
推荐模式:获取或创建¶
推荐的生产模式是首先检查会话是否存在,然后仅在需要时创建它。这种方法安全地处理新会话和对话恢复:
# Get or create session (handles both new sessions and reconnections)
session = await session_service.get_session(
app_name=APP_NAME,
user_id=user_id,
session_id=session_id
)
if not session:
await session_service.create_session(
app_name=APP_NAME,
user_id=user_id,
session_id=session_id
)
此模式在所有场景中都能正确工作:
- 新对话:如果会话不存在,则自动创建
- 恢复对话:如果会话已存在(例如,网络中断后重连),则重用现有会话并保留完整的对话历史记录
- 幂等:多次调用安全,不会出错
重要:在使用相同标识符调用 runner.run_live() 之前,会话必须存在。如果会话不存在,run_live() 将引发 ValueError: Session not found。
创建 RunConfig¶
RunConfig 定义了此特定会话的流式处理行为——使用哪种模态(文本或音频),是否启用转录、语音活动检测、主动性以及其他高级功能。
from google.adk.agents.run_config import RunConfig, StreamingMode
from google.genai import types
# Native audio models require AUDIO response modality with audio transcription
response_modalities = ["AUDIO"]
run_config = RunConfig(
streaming_mode=StreamingMode.BIDI,
response_modalities=response_modalities,
input_audio_transcription=types.AudioTranscriptionConfig(),
output_audio_transcription=types.AudioTranscriptionConfig(),
session_resumption=types.SessionResumptionConfig()
)
RunConfig 是特定于会话的——每个流式处理会话可以有不同的配置。例如,一个用户可能更喜欢纯文本响应,而另一个用户使用语音模式。有关完整的配置选项,请参阅 第 4 部分:理解 RunConfig。
创建 LiveRequestQueue¶
LiveRequestQueue 是流式处理期间向智能体发送消息的通信通道。它是一个线程安全的异步队列,缓冲用户消息(文本内容、音频 blob、活动信号)以便有序处理。
from google.adk.agents.live_request_queue import LiveRequestQueue
live_request_queue = LiveRequestQueue()
LiveRequestQueue 是特定于会话且有状态的——你为每个流式处理会话创建一个新队列,并在会话结束时关闭它。与 Agent 和 Runner 不同,队列不能跨会话重用。
每个会话一个队列
切勿跨多个流式处理会话重用 LiveRequestQueue。每次调用 run_live() 都需要一个新的队列。重用队列会导致消息顺序问题和状态损坏。
关闭信号将保留在队列中(参见 live_request_queue.py:66-67),并终止发送者循环(参见 base_llm_flow.py:628-630)。重用队列会结转此信号以及上一个会话中残留的任何消息。
第 3 阶段:使用 run_live() 事件循环进行双向流式处理¶
一旦流式处理循环运行,你可以并发地向智能体发送消息并接收响应——这就是行动中的双向流式处理。智能体可以在生成响应的同时,你发送新的输入,从而实现自然的基于中断的对话。
向智能体发送消息¶
使用 LiveRequestQueue 方法在流式处理会话期间向智能体发送不同类型的消息:
from google.genai import types
# Send text content
content = types.Content(parts=[types.Part(text=json_message["text"])])
live_request_queue.send_content(content)
# Send audio blob
audio_blob = types.Blob(
mime_type="audio/pcm;rate=16000",
data=audio_data
)
live_request_queue.send_realtime(audio_blob)
这些方法是非阻塞的——它们立即将消息添加到队列中,而无需等待处理。这即使在繁重的 AI 处理期间也能实现流畅、响应迅速的用户体验。
有关详细的 API 文档,请参阅 第 2 部分:使用 LiveRequestQueue 发送消息。
接收和处理事件¶
当智能体处理输入并生成响应时,run_live() 异步生成器会持续产生 Event 对象。每个事件代表一个离散的发生——部分文本生成、音频块、工具执行、转录、中断或回合完成。
async for event in runner.run_live(
user_id=user_id,
session_id=session_id,
live_request_queue=live_request_queue,
run_config=run_config
):
event_json = event.model_dump_json(exclude_none=True, by_alias=True)
await websocket.send_text(event_json)
事件专为流式传递而设计——你接收生成的部分响应,而不仅仅是完整的消息。这实现了实时 UI 更新和响应迅速的用户体验。
有关全面的事件处理模式,请参阅 第 3 部分:使用 run_live() 处理事件。
第 4 阶段:终止 Live API 会话¶
当流式处理会话应该结束时(用户断开连接、对话完成、发生超时),平滑地关闭队列以发出终止信号来终止 Live API 会话。
关闭队列¶
通过队列发送关闭信号以终止流式处理循环:
live_request_queue.close()
这向 run_live() 发出信号,停止产生事件并退出异步生成器循环。智能体完成任何正在进行的处理,流式处理会话干净地结束。
FastAPI 应用程序示例¶
这是一个完整的 FastAPI WebSocket 应用程序,展示了与适当的双向流式处理集成的所有四个阶段。关键模式是上行/下行任务:上行任务从 WebSocket 接收消息并将其发送到 LiveRequestQueue,而下行任务从 run_live() 接收 Event 对象并将其发送到 WebSocket。
完整演示实现
有关具有多模态支持(文本、音频、图像)的生产就绪实现,请参阅完整的 main.py 文件。
完整实现:
import asyncio
from fastapi import FastAPI, WebSocket, WebSocketDisconnect
from google.adk.runners import Runner
from google.adk.agents.run_config import RunConfig, StreamingMode
from google.adk.agents.live_request_queue import LiveRequestQueue
from google.adk.sessions import InMemorySessionService
from google.genai import types
from google_search_agent.agent import agent
# ========================================
# Phase 1: 应用程序初始化(启动时一次)
# ========================================
APP_NAME = "bidi-demo"
app = FastAPI()
# 定义你的会话服务
session_service = InMemorySessionService()
# 定义你的运行器
runner = Runner(
app_name=APP_NAME,
agent=agent,
session_service=session_service
)
# ========================================
# WebSocket 端点
# ========================================
@app.websocket("/ws/{user_id}/{session_id}")
async def websocket_endpoint(websocket: WebSocket, user_id: str, session_id: str) -> None:
await websocket.accept()
# ========================================
# Phase 2: 会话初始化(每个流式处理会话一次)
# ========================================
# 创建 RunConfig
response_modalities = ["AUDIO"]
run_config = RunConfig(
streaming_mode=StreamingMode.BIDI,
response_modalities=response_modalities,
input_audio_transcription=types.AudioTranscriptionConfig(),
output_audio_transcription=types.AudioTranscriptionConfig(),
session_resumption=types.SessionResumptionConfig()
)
# 获取或创建会话
session = await session_service.get_session(
app_name=APP_NAME,
user_id=user_id,
session_id=session_id
)
if not session:
await session_service.create_session(
app_name=APP_NAME,
user_id=user_id,
session_id=session_id
)
# 创建 LiveRequestQueue
live_request_queue = LiveRequestQueue()
# ========================================
# Phase 3: 活跃会话(并发双向通信)
# ========================================
async def upstream_task() -> None:
"""从 WebSocket 接收消息并发送到 LiveRequestQueue。"""
try:
while True:
# 从 WebSocket 接收文本消息
data: str = await websocket.receive_text()
# 发送到 LiveRequestQueue
content = types.Content(parts=[types.Part(text=data)])
live_request_queue.send_content(content)
except WebSocketDisconnect:
# 客户端断开连接 - 信号队列关闭
pass
async def downstream_task() -> None:
"""从 run_live() 接收事件并发送到 WebSocket。"""
async for event in runner.run_live(
user_id=user_id,
session_id=session_id,
live_request_queue=live_request_queue,
run_config=run_config
):
# 将事件作为 JSON 发送到 WebSocket
await websocket.send_text(
event.model_dump_json(exclude_none=True, by_alias=True)
)
# 并发运行两个任务
try:
await asyncio.gather(
upstream_task(),
downstream_task(),
return_exceptions=True
)
finally:
# ========================================
# Phase 4: 会话终止
# ========================================
# 始终关闭队列,即使发生异常
live_request_queue.close()
!!! note "需要异步上下文" {: #async-context-required }
所有 ADK 双向流式处理应用程序**必须在异步上下文中运行**。此要求来自多个组件:
- **`run_live()`**:ADK 的流式处理方法是一个没有同步包装器的异步生成器(与 `run()` 不同)
- **会话操作**:`get_session()` 和 `create_session()` 是异步方法
- **WebSocket 操作**:FastAPI 的 `websocket.accept()`、`receive_text()` 和 `send_text()` 都是异步的
- **并发任务**:上行/下行模式需要 `asyncio.gather()` 进行并发执行
本指南中的所有代码示例都假设你在异步上下文中运行(例如,在异步函数或协程中)。为了与 ADK 的官方文档模式保持一致,示例展示了没有样板包装函数的核心逻辑。
关键概念¶
上行任务 (WebSocket → LiveRequestQueue) {: #upstream-task-websocket-liverequestqueue }
上行任务持续从 WebSocket 客户端接收消息并将其转发到 LiveRequestQueue。这使用户能够随时向智能体发送消息,即使智能体正在生成响应。
async def upstream_task() -> None:
"""从 WebSocket 接收消息并发送到 LiveRequestQueue。"""
try:
while True:
data: str = await websocket.receive_text()
content = types.Content(parts=[types.Part(text=data)])
live_request_queue.send_content(content)
except WebSocketDisconnect:
pass # 客户端断开连接
下行任务 (run_live() → WebSocket) {: #downstream-task-run-live-websocket }
下行任务持续从 run_live() 接收 Event 对象并将其发送到 WebSocket 客户端。这将智能体的响应、工具执行、转录和其他事件实时流式传输给用户。
async def downstream_task() -> None:
"""从 run_live() 接收事件并发送到 WebSocket。"""
async for event in runner.run_live(
user_id=user_id,
session_id=session_id,
live_request_queue=live_request_queue,
run_config=run_config
):
await websocket.send_text(
event.model_dump_json(exclude_none=True, by_alias=True)
)
具有清理功能的并发执行 {: #concurrent-execution-with-cleanup }
两个任务使用 asyncio.gather() 并发运行,实现真正的双向流式处理。try/finally 块确保即使发生异常也会调用 LiveRequestQueue.close(),从而最大限度地减少会话资源使用。
try:
await asyncio.gather(
upstream_task(),
downstream_task(),
return_exceptions=True
)
finally:
live_request_queue.close() # 始终清理
这种模式——具有保证清理功能的并发上行/下行任务——是生产就绪流式处理应用程序的基础。生命周期模式(初始化一次,流式处理多次)实现了高效的资源使用和清晰的关注点分离,应用程序组件保持无状态和可重用,而特定于会话的状态隔离在 LiveRequestQueue、RunConfig 和会话记录中。
生产注意事项¶
此示例展示了核心模式。对于生产应用程序,请考虑:
- 错误处理(ADK):为 ADK 流式事件添加适当的错误处理。有关错误事件处理的详细信息,请参阅第 3 部分:错误事件。
- 在关闭期间捕获
asyncio.CancelledError,优雅地处理任务取消 - 使用
return_exceptions=True检查asyncio.gather()中的异常——异常不会自动传播
- 在关闭期间捕获
- 错误处理(Web):处理上行/下行任务中特定于 Web 应用程序的错误。例如,使用 FastAPI 时,你需要:
- 捕获
WebSocketDisconnect(客户端断开连接)、ConnectionClosedError(连接丢失)和RuntimeError(向已关闭的连接发送数据) - 在发送数据前使用
websocket.client_state验证 WebSocket 连接状态,以防止连接关闭时出错
- 捕获
- 身份验证和授权:为你的端点实现身份验证和授权
- 速率限制和配额:添加速率限制和超时控制。有关并发会话和配额管理的指导,请参阅第 4 部分:并发 Live API 会话和配额管理。
- 结构化日志记录:使用结构化日志记录进行调试。
- 持久化会话服务:考虑使用持久化会话服务(
DatabaseSessionService或VertexAiSessionService)。有关更多详细信息,请参阅 ADK 会话服务文档。
1.6 我们将学到什么¶
本指南将带你逐步了解 ADK Gemini Live API Toolkit 的架构,遵循流式处理应用程序的自然流程:消息如何从用户向上游传输到智能体,事件如何从智能体向下游流动到用户,如何配置会话行为,以及如何实现多模态特性。每一部分都侧重于流式处理架构的一个特定组件,并提供你可以立即应用的实用模式:
-
第 2 部分:使用 LiveRequestQueue 发送消息 - 了解 ADK 的
LiveRequestQueue如何提供用于处理文本、音频和控制消息的统一接口。你将了解LiveRequest消息模型,如何发送不同类型的内容,管理用户活动信号,以及通过单个平滑的 API 处理平滑的会话终止。 -
第 3 部分:使用 run_live() 处理事件 - 掌握 ADK 流式处理架构中的事件处理。了解如何处理不同的事件类型(文本、音频、转录、工具调用),使用中断和回合完成信号管理对话流,序列化事件以进行网络传输,并利用 ADK 的自动工具执行。理解事件处理对于构建响应迅速的流式处理应用程序至关重要。
-
第 4 部分:理解 RunConfig - 配置复杂的流式处理行为,包括多模态交互、智能主动性、会话恢复和成本控制。了解不同模型可用的功能,以及如何通过 RunConfig 声明式地控制你的流式处理会话。
-
第 5 部分:如何使用音频、图像和视频 - 使用 ADK 的多模态能力实现语音和视频功能。了解音频规格、流式处理架构、语音活动检测、音频转录以及构建自然语音 AI 体验的最佳实践。
先决条件和学习资源¶
为了在生产环境中构建 ADK Gemini Live API Toolkit 应用程序,我们建议具备以下技术的基础知识:
Google 的生产就绪框架,用于构建具有流式处理能力的 AI 智能体。ADK 为会话管理、工具编排和状态持久化提供了高级抽象,消除了从头开始实现低级流式处理基础设施的需要。
Live API (Gemini Live API and Gemini Live API (Agent Platform))
Google 的实时对话 AI 技术,支持与 Gemini 模型进行低延迟双向流式处理。Live API 提供了支持 ADK 流式处理能力的底层基于 WebSocket 的协议,处理多模态输入/输出和自然对话流。
Python 使用 async/await 语法和 asyncio 库对异步编程的内置支持。ADK 流式处理建立在异步生成器和协程之上,需要熟悉异步函数、等待任务和使用 asyncio.gather() 进行并发执行等概念。
一个使用 Python 类型注解进行数据验证和设置管理的 Python 库。ADK 广泛使用 Pydantic 模型来处理结构化数据(如 Event、RunConfig 和 Content),提供类型安全、自动验证和通过 .model_dump_json() 进行的 JSON 序列化。
一个现代、高性能的 Python Web 框架,用于构建具有自动 OpenAPI 文档的 API。FastAPI 对 WebSockets 和异步请求处理的原生支持使其成为构建 ADK 流式处理端点的理想选择。FastAPI 包含在 adk-python 包中,并由 ADK 的 adk web 工具用于快速原型设计。也可以使用其他支持 WebSocket 的框架(如 Flask-SocketIO 或 Starlette)。
一种通过单个 TCP 连接提供全双工(双向)通信通道的协议。WebSockets 实现了客户端和服务器之间的实时双向数据流,使其成为流式处理应用程序的标准传输方式。与 HTTP 请求 - 响应不同,WebSocket 连接持久存在,允许双方随时发送消息。
服务器通过 HTTP 向 Web 客户端推送数据的标准。与 WebSockets 不同,SSE 是单向的(仅服务器到客户端),使其更简单但不那么灵活。当你不需要客户端到服务器的流式处理时(例如当用户输入通过单独的 HTTP POST 请求进入时),SSE 对于流式传输智能体响应很有用。
虽然本指南彻底涵盖了 ADK 特定概念,但熟悉这些底层技术将帮助你构建更健壮的生产应用程序。
总结¶
在本介绍中,你了解了 ADK 如何将复杂的实时流式处理基础设施转变为开发人员友好的框架。我们涵盖了 Live API 双向流式处理能力的基础知识,通过 LiveRequestQueue、Runner 和 run_live() 等抽象检查了 ADK 如何简化流式处理复杂性,并探索了从初始化到会话终止的完整应用程序生命周期。你现在了解了 ADK 如何处理繁重的工作——LLM 端流式连接管理、状态持久化、平台差异和事件协调——因此你可以专注于构建智能智能体体验。有了这个基础,你准备好在接下来的部分中深入研究发送消息、处理事件、配置会话和实现多模态功能的细节。