使用搜索进行智能体基础信息获取 (Grounding)¶
Agent Search 是 Agent Development Kit (ADK) 的强大工具,使 AI 智能体能够从你的私有企业文档和数据仓库中访问信息。通过将智能体连接到索引化的企业内容,你可以为用户提供基于组织知识库的答案。
此功能对于需要内部文档、政策、研究论文或任何已在你的 Agent Search 数据存储中索引的专有内容的企业特定查询尤其有价值。当你的智能体确定需要来自知识库的信息时,它会自动搜索你索引的文档,并将结果以适当的归属方式纳入其响应中。
准备 Agent Search¶
在创建基于基础信息获取的智能体之前,你必须有一个现有的 Agent Search 数据存储。如果你还没有,请按照 自定义搜索入门 中的说明创建一个。配置智能体时,你需要使用你的 Data store ID(例如 projects/YOUR_PROJECT_ID/locations/global/collections/default_collection/dataStores/YOUR_DATASTORE_ID)。
身份验证设置¶
注意:Agent Search 需要 Google Cloud Platform (Agent Platform) 身份验证。此工具不支持 Google AI Studio。
- 设置 gcloud CLI。
- 通过在终端运行
gcloud auth login向 Google Cloud 进行身份验证。 - 对于 Python,打开
.env文件并指定你的项目 ID 和位置。 - 对于 Java,确保你的应用环境配置了 Google Cloud 默认凭据 (
GOOGLE_APPLICATION_CREDENTIALS)。
GOOGLE_GENAI_USE_ENTERPRISE=TRUE
GOOGLE_CLOUD_PROJECT=YOUR_PROJECT_ID
GOOGLE_CLOUD_LOCATION=LOCATION
有关从 ADK 智能体连接到 Google Cloud 的更多信息,请参阅连接 Google Cloud 和 Agent Platform。
创建基于搜索的 Grounded 智能体¶
要启用基于搜索的基础信息获取,你需要在智能体定义中包含搜索工具,并提供 data_store_id。
from google.adk.agents import Agent
from google.adk.tools import VertexAiSearchTool
# 配置
DATASTORE_ID = "projects/YOUR_PROJECT_ID/locations/global/collections/default_collection/dataStores/YOUR_DATASTORE_ID"
root_agent = Agent(
name="vertex_search_agent",
model="gemini-flash-latest",
instruction="使用 Agent Search 从内部文档中查找信息来回答问题。尽可能引用来源。",
description="具备 Agent Search 功能的企业文档搜索助手",
tools=[VertexAiSearchTool(data_store_id=DATASTORE_ID)]
)
import com.google.adk.agents.LlmAgent;
import com.google.adk.tools.VertexAiSearchTool;
// 配置
String DATASTORE_ID = "projects/YOUR_PROJECT_ID/locations/global/collections/default_collection/dataStores/YOUR_DATASTORE_ID";
LlmAgent rootAgent = LlmAgent.builder()
.name("vertex_search_agent")
.model("gemini-flash-latest")
.instruction("使用 Agent Search 从内部文档中查找信息来回答问题。尽可能引用来源。")
.description("具备 Agent Search 功能的企业文档搜索助手")
.tools(VertexAiSearchTool.builder().dataStoreId(DATASTORE_ID).build())
.build();
基于搜索的基础信息获取工作原理¶
基于搜索的基础信息获取是将你的智能体连接到组织索引文档和数据的过程,使其能够基于私有企业内容生成准确的响应。当用户的提示词需要来自内部知识库的信息时,智能体的底层 LLM 会智能地决定调用 VertexAiSearchTool 来从你索引的文档中查找相关事实。
数据流图¶
下图展示了从用户提问到 Grounded 响应的逐步流程。
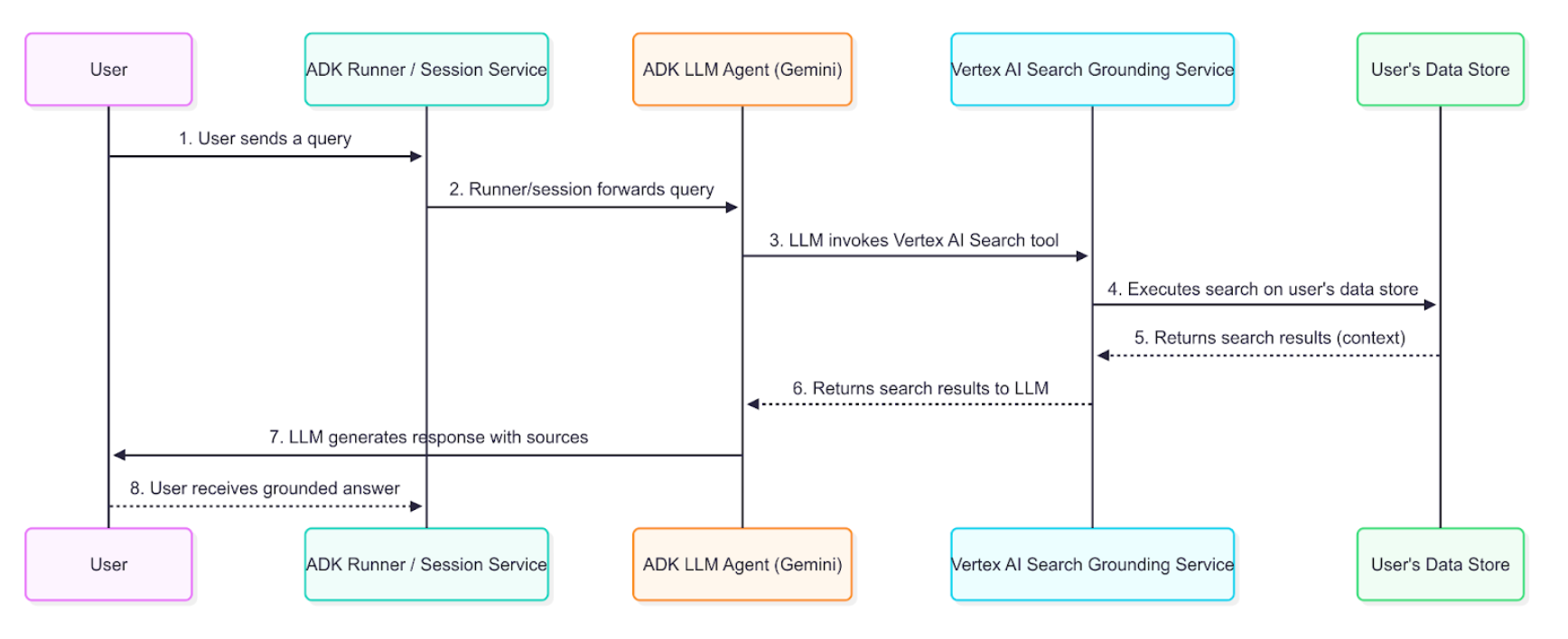
详细描述¶
Grounded 智能体使用上述数据流,从企业信息中检索、处理并整合到最终用户回复中。
- 用户查询 (User Query):最终用户通过询问有关内部文档或企业数据的问题与你的智能体进行交互。
- ADK 编排 (ADK Orchestration):Agent Development Kit 编排智能体的行为,并将用户的消息传递给智能体的核心。
- LLM 分析与工具调用 (LLM Analysis and Tool-Calling):智能体的 LLM(例如 Gemini 模型)分析提示词。如果确定需要从索引文档中获取信息,它会通过调用
VertexAiSearchTool触发基础信息获取机制。这对于回答有关公司政策、技术文档或专有研究的查询非常理想。 - Vertex AI 搜索服务交互 (Vertex AI Search Service Interaction):
VertexAiSearchTool与你配置的 Agent Search 数据存储交互,其中包含你索引的企业文档。该服务针对你的私有内容制定并执行搜索查询。 - 文档检索与排序 (Document Retrieval & Ranking):Agent Search 基于语义相似性和相关性评分从你的数据存储中检索并排序最相关的文档片段。
- 上下文注入 (Context Injection):搜索服务在生成最终响应之前将检索到的文档片段集成到模型的上下文中。这一关键步骤允许模型在你的组织事实数据上进行"推理"。
- 生成基础响应 (Grounded Response Generation):现在已了解相关企业内容的 LLM,生成包含从文档中检索到的信息的响应。
- 带来源的响应呈现 (Response Presentation with Sources):ADK 接收最终的基于基础信息获取的响应,其中包括必要的源文档引用和
groundingMetadata,并将其与归属信息一起呈现给用户。这允许最终用户根据你的企业来源验证信息。
理解基于搜索的基础信息获取响应¶
当智能体使用 Agent Search 来获取基础信息时,它会返回详细信息,包括最终文本答案和用于生成该答案的文档的元数据。此元数据对于验证响应和为你的企业来源提供归属至关重要。
Grounded 响应示例¶
以下是模型在针对企业文档进行 Grounded 查询后返回的内容对象示例。
最终答案文本:
"为医学速记员开发模型面临着几个重大挑战,这主要是由于医疗文档的复杂性、涉及的敏感数据以及临床工作流的严苛要求。主要挑战包括:**准确性和可靠性:** 医疗文档要求极高的准确性,因为错误可能导致误诊、错误的治疗以及法律后果。确保 AI 模型能可靠地捕捉细微的医学语言,区分主观和客观信息,并准确转录医患互动,是一个主要的障碍。**自然语言理解 (NLU) 和语音识别:** 医疗对话通常进行很快,涉及高度专业化的术语、首字母缩略词和缩写,并且说话者可能有不同的口音或说话模式……[响应继续,详细分析隐私、集成和技术挑战]"
Grounding 元数据片段:
{
"groundingMetadata": {
"groundingChunks": [
{
"document": {
"title": "AI in Medical Scribing: Technical Challenges",
"uri": "projects/your-project/locations/global/dataStores/your-datastore-id/documents/doc-medical-scribe-ai-tech-challenges",
"id": "doc-medical-scribe-ai-tech-challenges"
}
},
{
"document": {
"title": "Regulatory and Ethical Hurdles for AI in Healthcare",
"uri": "projects/your-project/locations/global/dataStores/your-datastore-id/documents/doc-ai-healthcare-ethics",
"id": "doc-ai-healthcare-ethics"
}
}
],
"groundingSupports": [
{
"groundingChunkIndices": [0, 1],
"segment": {
"endIndex": 637,
"startIndex": 433,
"text": "确保 AI 模型能可靠捕捉细致的医学语言……"
}
}
],
"retrievalQueries": [
"challenges in natural language processing medical domain",
"AI medical scribe challenges",
"difficulties in developing AI for medical scribes"
]
}
}
如何解读响应¶
元数据将模型生成的文本与企业文档建立了关联。分解如下:
- groundingChunks: 这是模型参考的企业文档列表。每个区块都包含文档标题
title、统一资源标识符uri(文档路径)和id。 - groundingSupports: 此列表将最终答案中的特定句子连接回
groundingChunks。 - segment: 此对象标识最终文本答案的一个特定部分,由其
startIndex、endIndex和文本本身定义。 - groundingChunkIndices: 此数组包含与
groundingChunks中列出的来源相对应的索引号。例如,关于“符合 HIPAA 标准”的文本由索引为 1 的groundingChunks(“监管与伦理障碍”文档)中的信息支持。 - retrievalQueries: 此数组显示了针对你的数据存储执行的特定搜索查询,以查找相关信息。
如何显示基于搜索的基础信息获取响应¶
与 Google 搜索基础信息获取不同,基于搜索的基础信息获取不需要特定的显示组件。但是,显示引用和文档引用可以建立信任,并允许用户根据组织的权威来源验证信息。
可选的引用显示¶
由于提供了基础信息获取元数据,你可以选择根据应用需求实现引用显示:
简易文本展示(最小实现):
增强型引用展示(可选): 你可以实现交互式引用,展示每句话由哪些文档支持。Grounding 元数据提供了将文本片段映射到来源文档的全部信息。
实现注意事项¶
在实现基于搜索的基础信息获取显示时:
- 文档访问:验证用户对所引用文档的访问权限。
- 简单集成:基础文本输出不需要额外的显示逻辑。
- 可选增强:仅在你的用例受益于来源归因时添加引用。
- 文档链接:必要时将文档 URI 转换为可访问的内部链接。
- 搜索查询:
retrievalQueries数组显示了针对你的数据存储执行了哪些搜索。