ADK 的 BigQuery 智能体分析插件¶
版本要求
使用 ADK 的 最新版本(版本 1.21.0 或更高版本)以充分利用本规范中描述的功能。
使用 ADK Python 版本 1.26.0 或更高版本,以充分利用本文档中描述的功能,包括自动模式升级、工具来源追踪和 HITL 事件跟踪。
BigQuery 智能体分析插件通过提供强大的深度智能体行为分析解决方案,显著增强了智能体开发工具包(ADK)。它利用 ADK 插件架构和 BigQuery Storage Write API,直接将关键操作事件捕获并记录到 Google BigQuery 表中,为你提供调试、实时监控和全面离线性能评估的高级功能。
Python 1.26.0 版本新增了自动模式升级(安全地向现有表添加新列)、工具来源追踪(LOCAL、MCP、SUB_AGENT、A2A、TRANSFER_AGENT、TRANSFER_A2A)以及用于人工参与互动的 HITL 事件追踪。1.27.0 版本新增了自动视图创建(生成扁平化、查询友好的事件视图)。
BigQuery Storage Write API
此功能使用 BigQuery Storage Write API,这是一项付费服务。 有关费用信息,请参阅 BigQuery 文档。
记录的智能体事件数据根据 ADK 事件类型而有所不同。如果你想了解更多信息,请参见 事件类型和负载。
- 智能体工作流调试与分析:将广泛的插件生命周期事件(LLM 调用、工具使用)和智能体产出事件(用户输入、模型响应)捕获到定义良好的模式中。
- 高量分析与调试:使用 Storage Write API 异步执行日志记录操作,以实现高吞吐量和低延迟。
- 多模态分析:记录和分析文本、图像及其他模态。大文件会卸载到 GCS,通过对象表可供 BigQuery ML 访问。
- 分布式追踪:内置对 OpenTelemetry 风格追踪(
trace_id、span_id)的支持,以可视化智能体执行流。 - 工具来源追踪:追踪每次工具调用的来源(本地函数、MCP 服务器、子智能体、A2A 远程智能体或传输智能体)。
- 人工参与(HITL)追踪:专用的事件类型用于凭据请求、确认提示和用户输入请求。
- 可查询事件视图:自动创建扁平化、按事件类型划分的 BigQuery 视图(例如
v_llm_request、v_tool_completed),通过展开 JSON 负载数据来简化下游分析。
捕获事件摘要¶
下表列出了插件记录的所有事件类型。有关详细的负载示例,请参见事件类型和负载。View 列显示了当启用 create_views(默认启用)时可选创建的 BigQuery 视图。
| 事件类型 | 捕获时机 | 关键负载字段 | 视图 |
|---|---|---|---|
USER_MESSAGE_RECEIVED |
用户消息进入调用 | text summary / content parts | v_user_message_received |
INVOCATION_STARTING |
调用开始 | (仅公共列) | v_invocation_starting |
INVOCATION_COMPLETED |
调用结束 | (仅公共列) | v_invocation_completed |
AGENT_STARTING |
智能体执行开始 | instruction summary | v_agent_starting |
AGENT_COMPLETED |
智能体执行结束 | latency | v_agent_completed |
LLM_REQUEST |
模型请求已发送 | model, prompt, config, tools | v_llm_request |
LLM_RESPONSE |
模型响应已接收 | response, usage tokens, cache metadata, latency, TTFT | v_llm_response |
LLM_ERROR |
模型调用失败 | error message, latency | v_llm_error |
TOOL_STARTING |
工具开始执行 | tool name, args, origin | v_tool_starting |
TOOL_COMPLETED |
工具执行成功 | tool name, result, origin, latency | v_tool_completed |
TOOL_ERROR |
工具执行失败 | tool name, args, origin, error, latency | v_tool_error |
STATE_DELTA |
会话状态变更 | state delta | v_state_delta |
HITL_CREDENTIAL_REQUEST |
凭据请求已发出 | synthetic tool name, args | v_hitl_credential_request |
HITL_CONFIRMATION_REQUEST |
确认请求已发出 | synthetic tool name, args | v_hitl_confirmation_request |
HITL_INPUT_REQUEST |
用户输入请求已发出 | synthetic tool name, args | v_hitl_input_request |
HITL_CREDENTIAL_REQUEST_COMPLETED |
用户提供凭据响应 | synthetic tool name, result | (仅基础表) |
HITL_CONFIRMATION_REQUEST_COMPLETED |
用户提供确认响应 | synthetic tool name, result | (仅基础表) |
HITL_INPUT_REQUEST_COMPLETED |
用户提供输入响应 | synthetic tool name, result | (仅基础表) |
A2A_INTERACTION |
远程 A2A 调用完成 | response, task ID, context ID, request/response | v_a2a_interaction |
AGENT_RESPONSE |
最终智能体响应已产出 | response (content), source event ID/author/branch (attributes) | v_agent_response |
快速入门¶
将插件添加到你的智能体的 App 对象中。前置条件请参见前置条件。
import os
from google.adk.agents import Agent
from google.adk.apps import App
from google.adk.models.google_llm import Gemini
from google.adk.plugins.bigquery_agent_analytics_plugin import BigQueryAgentAnalyticsPlugin
os.environ['GOOGLE_CLOUD_PROJECT'] = 'your-gcp-project-id'
os.environ['GOOGLE_CLOUD_LOCATION'] = 'us-central1'
os.environ['GOOGLE_GENAI_USE_VERTEXAI'] = 'True'
plugin = BigQueryAgentAnalyticsPlugin(
project_id="your-gcp-project-id",
dataset_id="your-big-query-dataset-id",
)
root_agent = Agent(
model=Gemini(model="gemini-flash-latest"),
name='my_agent',
instruction="You are a helpful assistant.",
)
app = App(
name="my_agent",
root_agent=root_agent,
plugins=[plugin],
)
将插件添加到你的运行器的插件列表中。前置条件请参见前置条件。
import com.google.adk.agents.LlmAgent;
import com.google.adk.agents.RunConfig;
import com.google.adk.models.Gemini;
import com.google.adk.plugins.Plugin;
import com.google.adk.plugins.agentanalytics.BigQueryAgentAnalyticsPlugin;
import com.google.adk.plugins.agentanalytics.BigQueryLoggerConfig;
import com.google.adk.runner.InMemoryRunner;
import com.google.common.collect.ImmutableList;
public final class Agent {
public static void main(String[] args) throws Exception {
Plugin bqLoggingPlugin = new BigQueryAgentAnalyticsPlugin(
BigQueryLoggerConfig.builder()
.projectId("your-gcp-project-id")
.datasetId("your-big-query-dataset-id")
.tableName("agent_events") // Optional, defaults to "events" in Java
.build());
InMemoryRunner runner = new InMemoryRunner(
LlmAgent.builder()
.model(Gemini.builder().modelName("gemini-2.5-flash").build())
.name("my_agent")
.instruction("You are a helpful assistant.")
.build(),
"my_agent",
ImmutableList.of(bqLoggingPlugin));
// Use runner ...
// Close runner to flush and close plugin
runner.close().blockingAwait();
}
}
运行并测试智能体¶
通过运行智能体并通过聊天界面发出一些请求来测试插件,例如"告诉我你能做什么"或"列出我的云项目
SELECT timestamp, event_type, content
FROM `your-gcp-project-id.your-big-query-dataset-id.agent_events`
ORDER BY timestamp DESC
LIMIT 20;
包含 GCS 卸载、OpenTelemetry 和 BigQuery 工具的完整示例
# my_bq_agent/agent.py
import os
import google.auth
from google.adk.apps import App
from google.adk.plugins.bigquery_agent_analytics_plugin import BigQueryAgentAnalyticsPlugin, BigQueryLoggerConfig
from google.adk.agents import Agent
from google.adk.models.google_llm import Gemini
from google.adk.tools.bigquery import BigQueryToolset, BigQueryCredentialsConfig
# --- OpenTelemetry TracerProvider Setup (Optional) ---
# ADK includes OpenTelemetry as a core dependency.
# Configuring a TracerProvider enables full distributed tracing
# (populates trace_id, span_id with standard OTel identifiers).
# If no TracerProvider is configured, the plugin falls back to internal
# UUIDs for span correlation while still preserving the parent-child hierarchy.
from opentelemetry import trace
from opentelemetry.sdk.trace import TracerProvider
trace.set_tracer_provider(TracerProvider())
# --- Configuration ---
PROJECT_ID = os.environ.get("GOOGLE_CLOUD_PROJECT", "your-gcp-project-id")
DATASET_ID = os.environ.get("BIG_QUERY_DATASET_ID", "your-big-query-dataset-id")
# GOOGLE_CLOUD_LOCATION must be a valid Agent Platform region (e.g., "us-central1").
# BQ_LOCATION is the BigQuery dataset location, which can be a multi-region
# like "US" or "EU", or a single region like "us-central1".
VERTEX_LOCATION = os.environ.get("GOOGLE_CLOUD_LOCATION", "us-central1")
BQ_LOCATION = os.environ.get("BQ_LOCATION", "US")
GCS_BUCKET = os.environ.get("GCS_BUCKET_NAME", "your-gcs-bucket-name") # Optional
if PROJECT_ID == "your-gcp-project-id":
raise ValueError("Please set GOOGLE_CLOUD_PROJECT or update the code.")
# --- CRITICAL: Set environment variables BEFORE Gemini instantiation ---
os.environ['GOOGLE_CLOUD_PROJECT'] = PROJECT_ID
os.environ['GOOGLE_CLOUD_LOCATION'] = VERTEX_LOCATION
os.environ['GOOGLE_GENAI_USE_VERTEXAI'] = 'True'
# --- Initialize the Plugin with Config ---
bq_config = BigQueryLoggerConfig(
enabled=True,
gcs_bucket_name=GCS_BUCKET, # Enable GCS offloading for multimodal content
log_multi_modal_content=True,
max_content_length=500 * 1024, # 500 KB limit for inline text
batch_size=1, # Default is 1 for low latency, increase for high throughput
shutdown_timeout=10.0
)
bq_logging_plugin = BigQueryAgentAnalyticsPlugin(
project_id=PROJECT_ID,
dataset_id=DATASET_ID,
table_id="agent_events", # default table name is agent_events
config=bq_config,
location=BQ_LOCATION
)
# --- Initialize Tools and Model ---
credentials, _ = google.auth.default(scopes=["https://www.googleapis.com/auth/cloud-platform"])
bigquery_toolset = BigQueryToolset(
credentials_config=BigQueryCredentialsConfig(credentials=credentials)
)
llm = Gemini(model="gemini-flash-latest")
root_agent = Agent(
model=llm,
name='my_bq_agent',
instruction="You are a helpful assistant with access to BigQuery tools.",
tools=[bigquery_toolset]
)
# --- Create the App ---
app = App(
name="my_bq_agent",
root_agent=root_agent,
plugins=[bq_logging_plugin],
)
package adk.plugins.agentanalytics.demo;
import static java.nio.charset.StandardCharsets.UTF_8;
import static java.util.Collections.singletonList;
import com.google.adk.agents.LlmAgent;
import com.google.adk.agents.RunConfig;
import com.google.adk.events.Event;
import com.google.adk.models.Gemini;
import com.google.adk.plugins.Plugin;
import com.google.adk.plugins.agentanalytics.BigQueryAgentAnalyticsPlugin;
import com.google.adk.plugins.agentanalytics.BigQueryLoggerConfig;
import com.google.adk.runner.InMemoryRunner;
import com.google.adk.sessions.Session;
import com.google.adk.tools.FunctionTool;
import com.google.adk.tools.ToolContext;
import com.google.genai.types.Content;
import com.google.genai.types.GenerateContentConfig;
import com.google.genai.types.Part;
import io.opentelemetry.sdk.OpenTelemetrySdk;
import io.opentelemetry.sdk.common.CompletableResultCode;
import io.opentelemetry.sdk.trace.SdkTracerProvider;
import io.opentelemetry.sdk.trace.data.SpanData;
import io.opentelemetry.sdk.trace.export.SimpleSpanProcessor;
import io.opentelemetry.sdk.trace.export.SpanExporter;
import io.reactivex.rxjava3.core.Flowable;
import java.util.Collection;
import java.util.Scanner;
/** Demo agent showing how to use BigQueryAgentAnalyticsPlugin. */
public final class BqDemoAgent {
private static final String PROJECT_ID = "your-gcp-project-id";
private static final String DATASET_ID = "your-gcp-dataset_id";
private static final String TABLE_ID = "your-gcp-table";
private static final String GCS_BUCKET_NAME = "your-gcs-bucket-name";
private static final String API_KEY = "your-api_key";
// A simple tool to demonstrate tool execution logging
public static String reverseString(String input, ToolContext toolContext) {
return new StringBuilder(input).reverse().toString();
}
public static void main(String[] args) throws Exception {
// 0. Initialize OpenTelemetry
initOpenTelemetry();
// 1. Configure the BigQuery Logger
BigQueryLoggerConfig config =
BigQueryLoggerConfig.builder()
.projectId(PROJECT_ID)
.datasetId(DATASET_ID)
.tableName(TABLE_ID)
.gcsBucketName(GCS_BUCKET_NAME)
.createViews(true)
.build();
// 2. Create the plugin instance
Plugin bqLoggingPlugin = new BigQueryAgentAnalyticsPlugin(config);
// 3. Initialize the model (Gemini)
Gemini model =
Gemini.builder()
.modelName("gemini-3-flash-preview") // Use appropriate model
.apiKey(API_KEY)
.build();
// 4. Create the agent with the tool and plugin
LlmAgent agent =
LlmAgent.builder()
.model(model)
.name("bq_demo_agent")
.instruction(
"You are a helpful assistant. You have a tool 'reverseString' that you can use to"
+ " reverse text.")
.tools(FunctionTool.create(BqDemoAgent.class, "reverseString"))
.generateContentConfig(GenerateContentConfig.builder().temperature(0.5f).build())
.build();
// 5. Initialize the runner
InMemoryRunner runner =
new InMemoryRunner(agent, "bq_demo_agent", singletonList(bqLoggingPlugin));
// 6. Create a session
Session session =
runner.sessionService().createSession(runner.appName(), "demo_user").blockingGet();
RunConfig runConfig = RunConfig.builder().build();
System.out.println("Agent ready. Type 'quit' to exit.");
try (Scanner scanner = new Scanner(System.in, UTF_8)) {
while (true) {
System.out.print("\nUser: ");
String userInput = scanner.nextLine();
if (userInput.trim().equalsIgnoreCase("quit")) {
break;
}
Content userMsg = Content.fromParts(Part.fromText(userInput));
// Run the agent and stream events
Flowable<Event> events =
runner.runAsync(session.userId(), session.id(), userMsg, runConfig);
System.out.print("Agent: ");
events.blockingForEach(
event -> {
if (event.finalResponse()) {
System.out.println(event.stringifyContent());
}
});
}
} finally {
System.out.println("Closing runner (flushing remaining logs)...");
runner.close().blockingAwait();
System.out.println("Done.");
}
}
private static void initOpenTelemetry() {
PrintingSpanExporter exporter = new PrintingSpanExporter();
SdkTracerProvider tracerProvider =
SdkTracerProvider.builder().addSpanProcessor(SimpleSpanProcessor.create(exporter)).build();
OpenTelemetrySdk.builder().setTracerProvider(tracerProvider).buildAndRegisterGlobal();
}
private static class PrintingSpanExporter implements SpanExporter {
@Override
public CompletableResultCode export(Collection<SpanData> spans) {
for (SpanData span : spans) {
System.out.println("--- Span: " + span.getName() + " ---");
System.out.println(" TraceId: " + span.getTraceId());
System.out.println(" SpanId: " + span.getSpanId());
System.out.println(" ParentSpanId: " + span.getParentSpanId());
System.out.println(" Attributes: " + span.getAttributes());
System.out.println("------------------------");
}
return CompletableResultCode.ofSuccess();
}
@Override
public CompletableResultCode flush() {
return CompletableResultCode.ofSuccess();
}
@Override
public CompletableResultCode shutdown() {
return CompletableResultCode.ofSuccess();
}
}
private BqDemoAgent() {}
}
部署到 Agent Runtime?
前置条件¶
- Google Cloud 项目,已启用 BigQuery API。
- BigQuery 数据集:在使用插件之前创建一个数据集来存储日志表。如果表不存在,插件会在数据集中自动创建必要的事件表。
- Google Cloud 存储桶(可选):如果你计划记录多模态内容(图像、音频等),建议创建一个 GCS 存储桶用于卸载大文件。
- 身份验证:
- 本地:运行
gcloud auth application-default login。 - 云端:确保你的服务账号具有所需权限。
- 本地:运行
注意:Gemini 模型选择器 gemini-flash-latest
ADK 文档中的大多数代码示例使用 gemini-flash-latest 来选择最新可用的 Gemini Flash 版本。但是,如果你通过区域端点(例如 us-central1)访问 Gemini,此选择字符串可能无效。在这种情况下,请使用 Gemini 模型页面或 Google Cloud Gemini 模型列表中的特定模型版本字符串。
IAM 权限¶
为了使智能体正常工作,运行智能体的主体(例如服务账号、用户账号)需要以下 Google Cloud 角色:
- 项目级别的
roles/bigquery.jobUser,用于运行 BigQuery 查询。 - 表级别的
roles/bigquery.dataEditor,用于写入日志/事件数据。 - 如果使用 GCS 卸载:目标存储桶上的
roles/storage.objectCreator和roles/storage.objectViewer。
配置选项¶
构造函数参数¶
BigQueryAgentAnalyticsPlugin 构造函数接受以下参数。它还接受 **kwargs,这些参数会直接转发给 BigQueryLoggerConfig(见下文)。
| 参数 | 类型 | 默认值 | 使用场景 |
|---|---|---|---|
project_id |
str |
(必填) | 选择 Google Cloud 项目 |
dataset_id |
str |
(必填) | 选择 BigQuery 数据集 |
table_id |
Optional[str] |
None |
使用自定义表名(覆盖 config 中的 table_id) |
config |
Optional[BigQueryLoggerConfig] |
None |
传入配置对象进行详细调优 |
location |
str |
"US" |
匹配 BigQuery 数据集位置(例如 "US"、"EU"、"us-central1") |
credentials |
Optional[google.auth.credentials.Credentials] |
None |
使用显式服务账号、模拟或跨项目凭据,替代 ADC |
plugin = BigQueryAgentAnalyticsPlugin(
project_id="my-project",
dataset_id="my_dataset",
batch_size=10, # forwarded to BigQueryLoggerConfig
shutdown_timeout=5.0, # forwarded to BigQueryLoggerConfig
)
BigQueryLoggerConfig 选项¶
以下所有选项均为可选的,并且具有合理的默认值。将它们传递给 BigQueryLoggerConfig 或作为 **kwargs 传递给插件构造函数。
| 选项 | 类型 | 默认值 | 使用场景 |
|---|---|---|---|
enabled |
bool |
True |
临时禁用日志记录 |
table_id |
str |
"agent_events" |
使用自定义表名(构造函数值优先) |
clustering_fields |
List[str] |
["event_type", "agent", "user_id"] |
自定义创建时的表聚类 |
gcs_bucket_name |
Optional[str] |
None |
将大文本和多模态内容卸载到 GCS |
connection_id |
Optional[str] |
None |
使用 BigQuery ObjectRef / 对象表(例如 us.my-connection) |
max_content_length |
int |
500 * 1024 |
在卸载/截断前控制内联负载大小 |
batch_size |
int |
1 |
调整写入吞吐量 vs 延迟 |
batch_flush_interval |
float |
1.0 |
定期刷新部分批次(秒) |
shutdown_timeout |
float |
10.0 |
关闭时等待最终刷新的时间(秒) |
event_allowlist |
Optional[List[str]] |
None |
仅记录选定的事件类型 |
event_denylist |
Optional[List[str]] |
None |
跳过敏感或噪音大的事件类型 |
content_formatter |
Optional[Callable] |
None |
为每个事件应用自定义脱敏/格式化(接收 (content, event_type)) |
log_multi_modal_content |
bool |
True |
捕获 content_parts 详情,包括 GCS 引用 |
queue_max_size |
int |
10000 |
限制内存事件队列 |
retry_config |
RetryConfig |
RetryConfig() |
调整重试行为(max_retries=3、initial_delay=1.0、multiplier=2.0、max_delay=10.0) |
log_session_metadata |
bool |
True |
将会话信息添加到 attributes(session_id、app_name、user_id、state)。前缀为 temp: 或 secret: 的键会被脱敏。 |
custom_tags |
Dict[str, Any] |
{} |
为每个事件的 attributes 添加静态标签(例如 {"env": "prod"}) |
auto_schema_upgrade |
bool |
True |
自动向现有表添加新列(仅添加) |
create_views |
bool |
True |
创建按事件类型划分的 BigQuery 视图(1.27.0+) |
view_prefix |
str |
"v" |
当多个插件共享一个数据集时避免视图名称冲突(例如 "v_staging") |
以下代码示例展示了如何为 BigQuery Agent Analytics 插件定义配置:
import json
import re
from google.adk.plugins.bigquery_agent_analytics_plugin import BigQueryLoggerConfig
def redact_dollar_amounts(event_content: Any, event_type: str) -> str:
"""
Custom formatter to redact dollar amounts (e.g., $600, $12.50)
and ensure JSON output if the input is a dict.
Args:
event_content: The raw content of the event.
event_type: The event type string (e.g., "LLM_REQUEST", "LLM_RESPONSE").
"""
text_content = ""
if isinstance(event_content, dict):
text_content = json.dumps(event_content)
else:
text_content = str(event_content)
# 使用正则表达式查找金额:$ 后跟数字,可选逗号或小数。
# 示例:$600、$1,200.50、$0.99
redacted_content = re.sub(r'\$\d+(?:,\d{3})*(?:\.\d+)?', 'xxx', text_content)
return redacted_content
config = BigQueryLoggerConfig(
enabled=True,
event_allowlist=["LLM_REQUEST", "LLM_RESPONSE"], # 仅记录这些事件
# event_denylist=["TOOL_STARTING"], # 跳过这些事件
shutdown_timeout=10.0, # 退出时最多等待 10 秒让日志刷新
max_content_length=500, # 将内容截断为 500 字符
content_formatter=redact_dollar_amounts, # 脱敏日志内容中的金额
queue_max_size=10000, # 内存中最多持有的事件数
auto_schema_upgrade=True, # 自动向现有表添加新列
create_views=True, # 自动创建按事件类型划分的视图
# retry_config=RetryConfig(max_retries=3), # 可选:配置重试
)
plugin = BigQueryAgentAnalyticsPlugin(
project_id="my-project",
dataset_id="my_dataset",
config=config,
)
在 Java 中,所有配置都通过 BigQueryLoggerConfig 构建器进行管理。
BigQueryLoggerConfig 构建器选项¶
| 构建器方法 | 类型 | 默认值 | 描述 |
|---|---|---|---|
enabled(boolean) |
boolean |
true |
临时禁用日志记录 |
projectId(String) |
String |
(必填) | 选择 Google Cloud 项目 |
datasetId(String) |
String |
"agent_analytics" |
选择 BigQuery 数据集 |
tableName(String) |
String |
"events" |
使用自定义表名(注意:默认为 "events",不同于 Python 的 "agent_events") |
location(String) |
String |
"us" |
匹配 BigQuery 数据集位置 |
clusteringFields(List<String>) |
List<String> |
["event_type", "agent", "user_id"] |
自定义创建时的表聚类 |
gcsBucketName(String) |
String |
"" |
将大文本和多模态内容卸载到 GCS |
connectionId(String) |
String |
null |
使用 BigQuery ObjectRef / 对象表 |
maxContentLength(int) |
int |
500 * 1024 |
在卸载/截断前控制内联负载大小 |
batchSize(int) |
int |
1 |
调整写入吞吐量 vs 延迟 |
batchFlushInterval(Duration) |
Duration |
Duration.ofSeconds(1) |
定期刷新部分批次 |
shutdownTimeout(Duration) |
Duration |
Duration.ofSeconds(10) |
关闭时等待最终刷新的时间 |
eventAllowlist(List<String>) |
List<String> |
[] |
仅记录选定的事件类型 |
eventDenylist(List<String>) |
List<String> |
[] |
跳过敏感或噪音大的事件类型 |
contentFormatter(BiFunction) |
BiFunction<Object, String, Object> |
null |
为每个事件应用自定义脱敏/格式化 |
logMultiModalContent(boolean) |
boolean |
true |
捕获 content_parts 详情,包括 GCS 引用 |
queueMaxSize(int) |
int |
10000 |
限制内存事件队列 |
retryConfig(RetryConfig) |
RetryConfig |
RetryConfig.builder().build() |
调整重试行为 |
logSessionMetadata(boolean) |
boolean |
true |
将会话信息添加到 attributes |
customTags(Map<String, Object>) |
Map<String, Object> |
{} |
为每个事件的 attributes 添加静态标签 |
autoSchemaUpgrade(boolean) |
boolean |
true |
自动向现有表添加新列 |
createViews(boolean) |
boolean |
false |
创建按事件类型划分的 BigQuery 视图(注意:默认为 false,不同于 Python 的 true) |
viewPrefix(String) |
String |
"v" |
避免视图名称冲突 |
credentials(Credentials) |
Credentials |
null |
使用显式服务账号凭据 |
以下代码示例展示了如何在 Java 中为 BigQuery Agent Analytics 插件定义配置:
import com.google.adk.plugins.agentanalytics.BigQueryAgentAnalyticsPlugin;
import com.google.adk.plugins.agentanalytics.BigQueryLoggerConfig;
import java.time.Duration;
import java.util.function.BiFunction;
// 用于脱敏金额的自定义格式化器
BiFunction<Object, String, Object> redactDollarAmounts = (content, eventType) -> {
String textContent = content.toString();
return textContent.replaceAll("\\$\\d+(?:,\\d{3})*(?:\\.\\d+)?", "xxx");
};
BigQueryLoggerConfig config = BigQueryLoggerConfig.builder()
.enabled(true)
.projectId("my-project")
.datasetId("my_dataset")
.tableName("agent_events")
.batchSize(1)
.batchFlushInterval(Duration.ofMillis(500))
.contentFormatter(redactDollarAmounts)
.autoSchemaUpgrade(true)
.createViews(true)
.build();
BigQueryAgentAnalyticsPlugin plugin = new BigQueryAgentAnalyticsPlugin(config);
模式与生产设置¶
模式参考¶
事件表(agent_events)使用灵活的模式。下表提供了包含示例值的全面参考。
| 字段名 | 类型 | 模式 | 描述 | 示例值 |
|---|---|---|---|---|
| timestamp | TIMESTAMP |
REQUIRED |
事件创建的 UTC 时间戳。作为主要排序键和每日分区键。精度为微秒。 | 2026-02-03 20:52:17 UTC |
| event_type | STRING |
NULLABLE |
标准事件类别。标准值包括 LLM_REQUEST、LLM_RESPONSE、LLM_ERROR、TOOL_STARTING、TOOL_COMPLETED、TOOL_ERROR、AGENT_STARTING、AGENT_COMPLETED、STATE_DELTA、INVOCATION_STARTING、INVOCATION_COMPLETED、USER_MESSAGE_RECEIVED 以及 HITL 事件(参见 HITL 事件)。用于高级过滤。 |
LLM_REQUEST |
| agent | STRING |
NULLABLE |
负责此事件的智能体名称。在智能体初始化时或通过 root_agent_name 上下文定义。 |
my_bq_agent |
| session_id | STRING |
NULLABLE |
整个对话线程的持久标识符。在多次轮次和子智能体调用中保持不变。 | 04275a01-1649-4a30-b6a7-5b443c69a7bc |
| invocation_id | STRING |
NULLABLE |
单次执行轮次或请求周期的唯一标识符。在许多上下文中对应于 trace_id。 |
e-b55b2000-68c6-4e8b-b3b3-ffb454a92e40 |
| user_id | STRING |
NULLABLE |
发起会话的用户(人类或系统)的标识符。从 User 对象或元数据中提取。 |
test_user |
| trace_id | STRING |
NULLABLE |
OpenTelemetry Trace ID(32 字符十六进制)。链接单个分布式请求生命周期中的所有操作。 | e-b55b2000-68c6-4e8b-b3b3-ffb454a92e40 |
| span_id | STRING |
NULLABLE |
OpenTelemetry Span ID(16 字符十六进制)。唯一标识此特定原子操作。 | 69867a836cd94798be2759d8e0d70215 |
| parent_span_id | STRING |
NULLABLE |
直接调用者的 Span ID。用于重建父子执行树(DAG)。 | ef5843fe40764b4b8afec44e78044205 |
| content | JSON |
NULLABLE |
主要事件负载。结构根据 event_type 而多态变化。 |
{"system_prompt": "You are...", "prompt": [{"role": "user", "content": "hello"}], "response": "Hi", "usage": {"total": 15}} |
| attributes | JSON |
NULLABLE |
元数据/增强信息(使用统计、模型信息、工具来源、自定义标签)。 | {"model": "gemini-flash-latest", "usage_metadata": {"total_token_count": 15}, "session_metadata": {"session_id": "...", "app_name": "...", "user_id": "...", "state": {}}, "custom_tags": {"env": "prod"}} |
| latency_ms | JSON |
NULLABLE |
性能指标。标准键为 total_ms(挂钟耗时)和 time_to_first_token_ms(流式延迟)。 |
{"total_ms": 1250, "time_to_first_token_ms": 450} |
| status | STRING |
NULLABLE |
高级别结果。值:OK(成功)或 ERROR(失败)。 |
OK |
| error_message | STRING |
NULLABLE |
人类可读的异常消息或堆栈跟踪片段。仅在 status 为 ERROR 时填充。 |
Error 404: Dataset not found |
| is_truncated | BOOLEAN |
NULLABLE |
如果 content 或 attributes 超过 BigQuery 单元格大小限制(默认 10MB)并被部分丢弃,则为 true。 |
false |
| content_parts | RECORD |
REPEATED |
多模态片段数组(文本、图像、Blob)。当内容无法序列化为简单 JSON 时使用(例如大二进制文件或 GCS 引用)。 | [{"mime_type": "text/plain", "text": "hello"}] |
如果表不存在,插件会自动创建。对于生产环境,你也可以选择使用下面的 DDL 手动创建表。
生产环境的 DDL
CREATE TABLE `your-gcp-project-id.adk_agent_logs.agent_events`
(
timestamp TIMESTAMP NOT NULL OPTIONS(description="记录事件时的 UTC 时间。"),
event_type STRING OPTIONS(description="指示所记录事件的类型(例如 'LLM_REQUEST'、'TOOL_COMPLETED')。"),
agent STRING OPTIONS(description="与此事件关联的 ADK 智能体或作者的名称。"),
session_id STRING OPTIONS(description="用于在单个对话或用户会话中对事件进行分组的唯一标识符。"),
invocation_id STRING OPTIONS(description="会话中每次智能体执行或轮次的唯一标识符。"),
user_id STRING OPTIONS(description="与当前会话关联的用户标识符。"),
trace_id STRING OPTIONS(description="用于分布式追踪的 OpenTelemetry trace ID。"),
span_id STRING OPTIONS(description="此特定操作的 OpenTelemetry span ID。"),
parent_span_id STRING OPTIONS(description="用于重建层次结构的 OpenTelemetry 父 span ID。"),
content JSON OPTIONS(description="以 JSON 形式存储的事件特定数据(负载)。"),
content_parts ARRAY<STRUCT<
mime_type STRING,
uri STRING,
object_ref STRUCT<
uri STRING,
version STRING,
authorizer STRING,
details JSON
>,
text STRING,
part_index INT64,
part_attributes STRING,
storage_mode STRING
>> OPTIONS(description="多模态数据的详细内容片段。"),
attributes JSON OPTIONS(description="用于附加元数据的任意键值对(例如 'root_agent_name'、'model_version'、'usage_metadata'、'session_metadata'、'custom_tags')。"),
latency_ms JSON OPTIONS(description="延迟测量值(例如 total_ms)。"),
status STRING OPTIONS(description="事件的结果,通常为 'OK' 或 'ERROR'。"),
error_message STRING OPTIONS(description="如果发生错误则填充。"),
is_truncated BOOLEAN OPTIONS(description="标志位,指示内容是否被截断。"
)
PARTITION BY DATE(timestamp)
CLUSTER BY event_type, agent, user_id;
自动创建的视图(1.27.0+)¶
当 create_views=True(1.27.0 及更高版本的默认值)时,插件会自动为每种事件类型生成视图,将常见的 JSON 结构展开为扁平化的类型列。这大大简化了 SQL,无需显式编写复杂的 JSON_VALUE 或 JSON_QUERY 函数。
视图名称遵循 {view_prefix}_{event_type_lowercase} 的约定(例如,使用默认前缀 "v" 时,LLM_REQUEST 变为 v_llm_request)。当多个插件实例写入同一数据集中的不同表时,在 BigQueryLoggerConfig 中设置 view_prefix 为不同的值,以防止视图名称冲突:
# 同一数据集中的两个插件,使用不同的视图前缀
plugin_prod = BigQueryAgentAnalyticsPlugin(
project_id=PROJECT_ID, dataset_id=DATASET_ID,
table_id="agent_events_prod",
config=BigQueryLoggerConfig(view_prefix="v_prod"),
)
# 创建视图:v_prod_llm_request、v_prod_tool_completed 等
plugin_staging = BigQueryAgentAnalyticsPlugin(
project_id=PROJECT_ID, dataset_id=DATASET_ID,
table_id="agent_events_staging",
config=BigQueryLoggerConfig(view_prefix="v_staging"),
)
# 创建视图:v_staging_llm_request、v_staging_tool_completed 等
你也可以调用公共异步方法 await plugin.create_analytics_views() 来手动刷新视图,例如在模式升级之后。
每个视图都包含以下公共列:timestamp、event_type、agent、session_id、invocation_id、user_id、trace_id、span_id、parent_span_id、status、error_message、is_truncated。
下表列出了所有自动创建的视图及其事件专用列:
| 视图名称 | 事件专用列 |
|---|---|
v_user_message_received |
(仅公共列) |
v_llm_request |
model (STRING), request_content (JSON), llm_config (JSON), tools (JSON) |
v_llm_response |
response (JSON), usage_prompt_tokens (INT64), usage_completion_tokens (INT64), usage_total_tokens (INT64), usage_cached_tokens (INT64), total_ms (INT64), ttft_ms (INT64), model_version (STRING), usage_metadata (JSON), cache_metadata (JSON), context_cache_hit_rate (FLOAT64) |
v_llm_error |
total_ms (INT64) |
v_tool_starting |
tool_name (STRING), tool_args (JSON), tool_origin (STRING) |
v_tool_completed |
tool_name (STRING), tool_result (JSON), tool_origin (STRING), total_ms (INT64) |
v_tool_error |
tool_name (STRING), tool_args (JSON), tool_origin (STRING), total_ms (INT64) |
v_agent_starting |
agent_instruction (STRING) |
v_agent_completed |
total_ms (INT64) |
v_invocation_starting |
(仅公共列) |
v_invocation_completed |
(仅公共列) |
v_state_delta |
state_delta (JSON) |
v_hitl_credential_request |
tool_name (STRING), tool_args (JSON) |
v_hitl_confirmation_request |
tool_name (STRING), tool_args (JSON) |
v_hitl_input_request |
tool_name (STRING), tool_args (JSON) |
v_a2a_interaction |
response_content (JSON), a2a_task_id (STRING), a2a_context_id (STRING), a2a_request (JSON), a2a_response (JSON) |
v_agent_response |
response_text (STRING), source_event_id (STRING), source_event_author (STRING), source_event_branch (STRING) |
事件类型和负载¶
content 列现在包含一个特定于 event_type 的 JSON 对象。content_parts 列提供了内容的结构化视图,特别适用于图像或已卸载的数据。
内容截断
- 可变内容字段会被截断至
max_content_length(在BigQueryLoggerConfig中配置,默认 500KB)。 - 如果配置了
gcs_bucket_name,大内容会卸载到 GCS 而非截断,并在content_parts.object_ref中存储引用。
LLM 交互(插件生命周期)¶
这些事件追踪发送给 LLM 的原始请求和从 LLM 接收的响应。
1. LLM_REQUEST
捕获发送给模型的提示,包括对话历史和系统指令。
{
"event_type": "LLM_REQUEST",
"content": {
"system_prompt": "You are a helpful assistant...",
"prompt": [
{
"role": "user",
"content": "hello how are you today"
}
]
},
"attributes": {
"root_agent_name": "my_bq_agent",
"model": "gemini-flash-latest",
"tools": ["list_dataset_ids", "execute_sql"],
"llm_config": {
"temperature": 0.5,
"top_p": 0.9
}
}
}
2. LLM_RESPONSE
捕获模型的输出和 token 使用统计。
{
"event_type": "LLM_RESPONSE",
"content": {
"response": "text: 'Hello! I'm doing well...'",
"usage": {
"completion": 19,
"prompt": 10129,
"total": 10148
}
},
"attributes": {
"root_agent_name": "my_bq_agent",
"model_version": "gemini-flash-latest",
"usage_metadata": {
"prompt_token_count": 10129,
"candidates_token_count": 19,
"total_token_count": 10148
}
},
"latency_ms": {
"time_to_first_token_ms": 2579,
"total_ms": 2579
}
}
3. LLM_ERROR
当 LLM 调用因异常失败时记录。错误消息会被捕获,并且 span 被关闭。
{
"event_type": "LLM_ERROR",
"content": null,
"attributes": {
"root_agent_name": "my_bq_agent"
},
"error_message": "Error 429: Resource exhausted",
"latency_ms": {
"total_ms": 350
}
}
工具使用(插件生命周期)¶
这些事件追踪智能体对工具的执行情况。每个工具事件包含一个 tool_origin 字段,用于分类工具的来源:
| 工具来源 | 描述 |
|---|---|
LOCAL |
FunctionTool 实例(本地 Python 函数) |
MCP |
模型上下文协议工具(McpTool 实例) |
SUB_AGENT |
AgentTool 实例(子智能体) |
A2A |
远程 Agent2Agent 实例(RemoteA2aAgent) |
TRANSFER_AGENT |
TransferToAgentTool 实例(通用智能体传输) |
TRANSFER_A2A |
传输到 RemoteA2aAgent 的 TransferToAgentTool 实例(在调用级别分类) |
UNKNOWN |
未分类的工具 |
4. TOOL_STARTING
当智能体开始执行工具时记录。
{
"event_type": "TOOL_STARTING",
"content": {
"tool": "list_dataset_ids",
"args": {
"project_id": "bigquery-public-data"
},
"tool_origin": "LOCAL"
}
}
5. TOOL_COMPLETED
当工具执行完成时记录。
{
"event_type": "TOOL_COMPLETED",
"content": {
"tool": "list_dataset_ids",
"result": [
"austin_311",
"austin_bikeshare"
],
"tool_origin": "LOCAL"
},
"latency_ms": {
"total_ms": 467
}
}
6. TOOL_ERROR
当工具执行因异常失败时记录。捕获工具名称、参数、工具来源和错误消息。
{
"event_type": "TOOL_ERROR",
"content": {
"tool": "list_dataset_ids",
"args": {
"project_id": "nonexistent-project"
},
"tool_origin": "LOCAL"
},
"error_message": "Error 404: Dataset not found",
"latency_ms": {
"total_ms": 150
}
}
状态管理¶
这些事件追踪智能体状态的变更,通常由工具触发。
7. STATE_DELTA
追踪智能体内部状态的变更(例如,由工具更新的自定义应用程序状态)。
内置脱敏
以 temp: 或 secret: 为前缀的状态键在记录的 state_delta 中会自动脱敏为 [REDACTED]。详见内置脱敏。
{
"event_type": "STATE_DELTA",
"attributes": {
"state_delta": {
"customer_tier": "enterprise",
"last_query_dataset": "bigquery-public-data.samples"
}
}
}
智能体生命周期和通用事件¶
| 事件类型 | 内容(JSON)结构 |
|---|---|
INVOCATION_STARTING |
{} |
INVOCATION_COMPLETED |
{} |
AGENT_STARTING |
"You are a helpful agent..." |
AGENT_COMPLETED |
{} |
USER_MESSAGE_RECEIVED |
{"text_summary": "Help me book a flight."} |
AGENT_RESPONSE |
{"response": "Here are the flights..."} |
AGENT_RESPONSE
当智能体向用户产出最终响应时记录。响应文本存储在 content 中,而源事件元数据存储在 attributes 中。
{
"event_type": "AGENT_RESPONSE",
"content": {
"response": "Here are the available flights..."
},
"attributes": {
"source_event_id": "evt-abc123",
"source_event_author": "flight_agent",
"source_event_branch": "main"
}
}
人工参与(HITL)事件¶
插件会自动检测对 ADK 合成 HITL 工具的调用,并为它们发出专用的事件类型。这些事件在正常的 TOOL_STARTING / TOOL_COMPLETED 事件之外额外记录。
识别以下 HITL 工具名称:
adk_request_credential:请求用户凭据(例如 OAuth 令牌)adk_request_confirmation:请求用户确认后再继续adk_request_input:请求自由格式的用户输入
| 事件类型 | 触发条件 | 内容(JSON)结构 |
|---|---|---|
HITL_CREDENTIAL_REQUEST |
智能体调用 adk_request_credential |
{"tool": "adk_request_credential", "args": {...}} |
HITL_CREDENTIAL_REQUEST_COMPLETED |
用户提供凭据响应 | {"tool": "adk_request_credential", "result": {...}} |
HITL_CONFIRMATION_REQUEST |
智能体调用 adk_request_confirmation |
{"tool": "adk_request_confirmation", "args": {...}} |
HITL_CONFIRMATION_REQUEST_COMPLETED |
用户提供确认响应 | {"tool": "adk_request_confirmation", "result": {...}} |
HITL_INPUT_REQUEST |
智能体调用 adk_request_input |
{"tool": "adk_request_input", "args": {...}} |
HITL_INPUT_REQUEST_COMPLETED |
用户提供输入响应 | {"tool": "adk_request_input", "result": {...}} |
HITL 请求事件通过 on_event_callback 中的 function_call 片段检测。HITL 完成事件通过 on_event_callback 和 on_user_message_callback 中的 function_response 片段检测。
HITL 事件的视图
自动创建的视图仅适用于三种请求事件类型(v_hitl_credential_request、v_hitl_confirmation_request、v_hitl_input_request)。三种 *_COMPLETED 事件类型会记录到基础表,但没有专用视图。直接从 agent_events 表中使用 WHERE event_type LIKE 'HITL_%_COMPLETED' 查询。
A2A 交互事件¶
当你的智能体通过 Agent2Agent(A2A)协议与远程智能体通信时,插件会记录一个 A2A_INTERACTION 事件,捕获请求和响应详情。
A2A_INTERACTION
当 A2A 远程智能体调用完成时记录。
{
"event_type": "A2A_INTERACTION",
"content": {
"response_content": "The remote agent's response...",
"a2a_task_id": "task-abc123",
"a2a_context_id": "ctx-def456",
"a2a_request": { ... },
"a2a_response": { ... }
}
}
存储行为:GCS 卸载¶
当在 BigQueryLoggerConfig 中配置了 gcs_bucket_name 时,插件会自动将大文本和多模态内容(图像、音频等)卸载到 Google Cloud Storage。content 列将包含摘要或占位符,而 content_parts 则存储指向 GCS URI 的 object_ref。另请参见配置选项中的 connection_id 和 max_content_length。
卸载文本示例¶
{
"event_type": "LLM_REQUEST",
"content_parts": [
{
"part_index": 1,
"mime_type": "text/plain",
"storage_mode": "GCS_REFERENCE",
"text": "AAAA... [OFFLOADED]",
"object_ref": {
"uri": "gs://sample-bucket-name/2025-12-10/e-f9545d6d/ae5235e6_p1.txt",
"authorizer": "us.bqml_connection",
"details": {"gcs_metadata": {"content_type": "text/plain"}}
}
}
]
}
卸载图像示例¶
{
"event_type": "LLM_REQUEST",
"content_parts": [
{
"part_index": 2,
"mime_type": "image/png",
"storage_mode": "GCS_REFERENCE",
"text": "[MEDIA OFFLOADED]",
"object_ref": {
"uri": "gs://sample-bucket-name/2025-12-10/e-f9545d6d/ae5235e6_p2.png",
"authorizer": "us.bqml_connection",
"details": {"gcs_metadata": {"content_type": "image/png"}}
}
}
]
}
查询卸载内容(获取签名 URL)¶
SELECT
timestamp,
event_type,
part.mime_type,
part.storage_mode,
part.object_ref.uri AS gcs_uri,
-- Generate a signed URL to read the content directly (requires connection_id configuration)
STRING(OBJ.GET_ACCESS_URL(part.object_ref, 'r').access_urls.read_url) AS signed_url
FROM `your-gcp-project-id.your-dataset-id.agent_events`,
UNNEST(content_parts) AS part
WHERE part.storage_mode = 'GCS_REFERENCE'
ORDER BY timestamp DESC
LIMIT 10;
查询示例¶
调试运行¶
使用 trace_id 追踪特定对话轮次¶
SELECT timestamp, event_type, agent, JSON_VALUE(content, '$.response') as summary
FROM `your-gcp-project-id.your-dataset-id.agent_events`
WHERE trace_id = 'your-trace-id'
ORDER BY timestamp ASC;
Span 层次结构和耗时分析¶
SELECT
span_id,
parent_span_id,
event_type,
timestamp,
-- 从 latency_ms 中提取已完成操作的持续时间
CAST(JSON_VALUE(latency_ms, '$.total_ms') AS INT64) as duration_ms,
-- 标识特定工具或操作
COALESCE(
JSON_VALUE(content, '$.tool'),
'LLM_CALL'
) as operation
FROM `your-gcp-project-id.your-dataset-id.agent_events`
WHERE trace_id = 'your-trace-id'
AND event_type IN ('LLM_RESPONSE', 'TOOL_COMPLETED')
ORDER BY timestamp ASC;
错误分析(LLM 和工具错误)¶
使用视图(推荐):
-- 带有来源信息的工具错误
SELECT timestamp, agent, tool_name, tool_origin, error_message, total_ms
FROM `your-gcp-project-id.your-dataset-id.v_tool_error`
ORDER BY timestamp DESC
LIMIT 20;
-- LLM 错误
SELECT timestamp, agent, error_message, total_ms
FROM `your-gcp-project-id.your-dataset-id.v_llm_error`
ORDER BY timestamp DESC
LIMIT 20;
监控成本和性能¶
Token 使用分析¶
使用 v_llm_response 视图(推荐):
SELECT
AVG(usage_total_tokens) as avg_tokens,
AVG(usage_prompt_tokens) as avg_prompt_tokens,
AVG(usage_completion_tokens) as avg_completion_tokens
FROM `your-gcp-project-id.your-dataset-id.v_llm_response`;
或者使用基础表配合 JSON 提取:
SELECT
AVG(CAST(JSON_VALUE(content, '$.usage.total') AS INT64)) as avg_tokens
FROM `your-gcp-project-id.your-dataset-id.agent_events`
WHERE event_type = 'LLM_RESPONSE';
延迟分析(LLM 和工具)¶
使用视图(推荐):
-- LLM 延迟
SELECT AVG(total_ms) as avg_llm_ms, AVG(ttft_ms) as avg_ttft_ms
FROM `your-gcp-project-id.your-dataset-id.v_llm_response`;
-- 按工具名称统计的工具延迟
SELECT tool_name, tool_origin, AVG(total_ms) as avg_tool_ms
FROM `your-gcp-project-id.your-dataset-id.v_tool_completed`
GROUP BY tool_name, tool_origin
ORDER BY avg_tool_ms DESC;
或者使用基础表:
SELECT
event_type,
AVG(CAST(JSON_VALUE(latency_ms, '$.total_ms') AS INT64)) as avg_latency_ms
FROM `your-gcp-project-id.your-dataset-id.agent_events`
WHERE event_type IN ('LLM_RESPONSE', 'TOOL_COMPLETED')
GROUP BY event_type;
检查工具和交互¶
工具来源分析¶
使用 v_tool_completed 视图(推荐):
SELECT
tool_origin,
tool_name,
COUNT(*) as call_count,
AVG(total_ms) as avg_latency_ms
FROM `your-gcp-project-id.your-dataset-id.v_tool_completed`
GROUP BY tool_origin, tool_name
ORDER BY call_count DESC;
HITL 交互分析¶
SELECT
timestamp,
event_type,
session_id,
JSON_VALUE(content, '$.tool') as hitl_tool,
content
FROM `your-gcp-project-id.your-dataset-id.agent_events`
WHERE event_type LIKE 'HITL_%'
ORDER BY timestamp DESC
LIMIT 20;
分析多模态内容¶
查询多模态内容(使用 content_parts 和 ObjectRef)¶
SELECT
timestamp,
part.mime_type,
part.object_ref.uri as gcs_uri
FROM `your-gcp-project-id.your-dataset-id.agent_events`,
UNNEST(content_parts) as part
WHERE part.mime_type LIKE 'image/%'
ORDER BY timestamp DESC;
使用 BigQuery 远程模型(Gemini)分析多模态内容¶
SELECT
logs.session_id,
-- 获取图像的签名 URL
STRING(OBJ.GET_ACCESS_URL(parts.object_ref, "r").access_urls.read_url) as signed_url,
-- 使用远程模型分析图像(例如 gemini-pro-vision)
AI.GENERATE(
('Describe this image briefly. What company logo?', parts.object_ref)
) AS generated_result
FROM
`your-gcp-project-id.your-dataset-id.agent_events` logs,
UNNEST(logs.content_parts) AS parts
WHERE
parts.mime_type LIKE 'image/%'
ORDER BY logs.timestamp DESC
LIMIT 1;
AI 驱动的根因分析¶
使用 BigQuery ML 和 Gemini 自动分析失败的会话,以确定错误的根本原因。
DECLARE failed_session_id STRING;
-- 查找最近的失败会话
SET failed_session_id = (
SELECT session_id
FROM `your-gcp-project-id.your-dataset-id.agent_events`
WHERE error_message IS NOT NULL
ORDER BY timestamp DESC
LIMIT 1
);
-- 重建完整对话上下文
WITH SessionContext AS (
SELECT
session_id,
STRING_AGG(CONCAT(event_type, ': ', COALESCE(TO_JSON_STRING(content), '')), '\n' ORDER BY timestamp) as full_history
FROM `your-gcp-project-id.your-dataset-id.agent_events`
WHERE session_id = failed_session_id
GROUP BY session_id
)
-- 让 Gemini 诊断问题
SELECT
session_id,
AI.GENERATE(
('分析此对话日志并解释失败的根本原因。日志:', full_history),
endpoint => 'gemini-flash-latest'
).result AS root_cause_explanation
FROM SessionContext;
对话分析¶
你还可以使用 BigQuery 对话分析通过自然语言分析你的智能体日志。在BigQuery Agents Hub中创建一个连接到你的 agent_events 表的对话分析智能体,然后提出如下问题:
- "显示随时间变化的错误率"
- "最常见的工具调用是什么?"
- "找出 token 使用量高的会话"
将带插件的智能体部署到 Agent Runtime¶
The context graph¶
Beyond row-level agent_events, the BigQuery Agent Analytics
SDK can
materialize a context graph: a queryable BigQuery property
graph of your
agent's decisions — the requests it handled, the options it weighed, and the
outcomes it chose. It lets you trace why a decision happened with Graph Query
Language (GQL), not just that an event was logged.
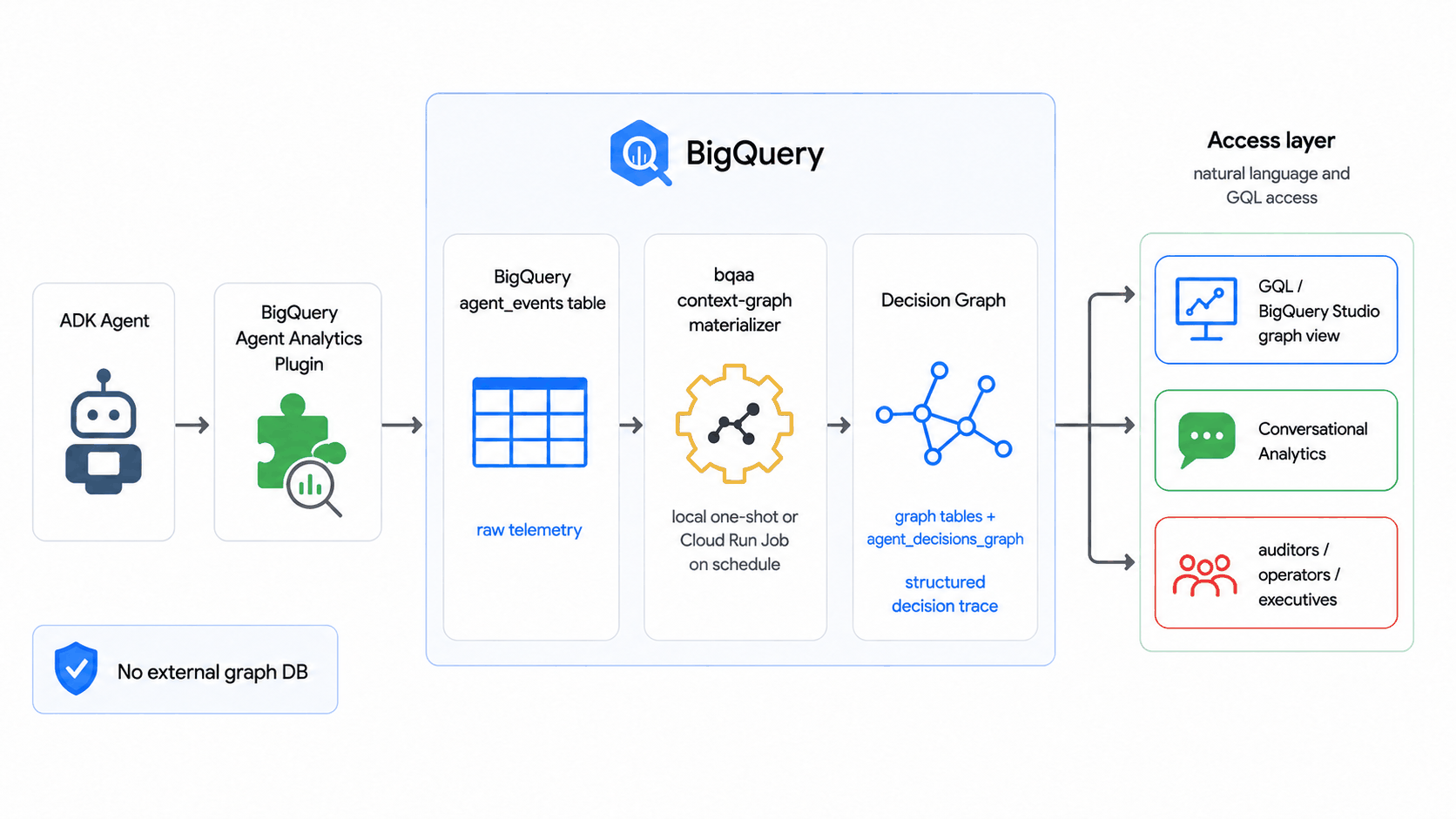
The graph is defined by two declarative artifacts — your table DDL and a CREATE
PROPERTY GRAPH schema — and the SDK's bqaa context-graph --property-graph
command derives the extraction (which entities and relationships to pull, and
their column types) from them plus your live table schemas. No separate ontology
or binding file is required for the common case; reach for an explicit
ontology.yaml / binding.yaml only when you need descriptions to steer the AI
prompt, entity inheritance, derived properties, or column renames.
Run it once locally, or on a schedule as a Cloud Run Job triggered by Cloud Scheduler — with split read-only-events / writable-graph datasets, least-privilege service accounts, structured JSON logs, and Cloud Monitoring alerts. The operational reference (prerequisites, the IAM matrix, recommended schedules, the JSON log shape, monitoring, and teardown) lives in the SDK repo:
- Periodic materialization codelab — build and query a decision graph end to end.
- Scheduled deploy runbook — take that graph to a hands-off scheduled deploy.
- Deploy reference (Cloud Run + Cloud Scheduler) — the full IAM matrix, schedules, monitoring, and the Terraform module.
Deploy to Agent Runtime with the plugin¶
版本要求
使用此插件部署到 Agent Runtime 需要 ADK Python 版本 1.24.0 或更高。早期版本存在一个问题,即在刷新待处理事件之前,插件异步日志写入器可能被无服务器运行时终止。从 1.24.0 开始,该插件在每次调用结束时执行同步刷新,以确保所有事件都被写入。
前置条件¶
在部署之前,请确保你已完成常规的 Agent Runtime 设置,包括:
- 一个已启用 Agent Platform API 和 Cloud Resource Manager API 的 Google Cloud 项目。
- 目标项目中的 BigQuery 数据集(或具有正确权限的跨项目数据集)。
- 用于部署工件的 Cloud Storage 暂存存储桶。
- 部署服务账号具有 IAM 权限中列出的 IAM 角色。
- 你的编码环境已使用
gcloud auth login和gcloud auth application-default login完成身份验证。
步骤 1:定义智能体和插件¶
创建一个包含插件的 App 对象的智能体项目文件夹。对于带有插件的 Agent Runtime 部署,App 对象是必需的。
import os
import google.auth
from google.adk.agents import Agent
from google.adk.apps import App
from google.adk.models.google_llm import Gemini
from google.adk.plugins.bigquery_agent_analytics_plugin import (
BigQueryAgentAnalyticsPlugin,
BigQueryLoggerConfig,
)
from google.adk.tools.bigquery import BigQueryToolset, BigQueryCredentialsConfig
# --- Configuration ---
PROJECT_ID = os.environ.get("GOOGLE_CLOUD_PROJECT", "your-gcp-project-id")
DATASET_ID = os.environ.get("BQ_DATASET", "agent_analytics")
# BQ_LOCATION 是 BigQuery 数据集位置(多区域 "US"/"EU" 或
# 单个区域如 "us-central1")。这与 GOOGLE_CLOUD_LOCATION 使用的 Agent Platform
# 区域不同。
BQ_LOCATION = os.environ.get("BQ_LOCATION", "US")
os.environ["GOOGLE_GENAI_USE_VERTEXAI"] = "True"
# --- 插件 ---
bq_analytics_plugin = BigQueryAgentAnalyticsPlugin(
project_id=PROJECT_ID,
dataset_id=DATASET_ID,
location=BQ_LOCATION,
config=BigQueryLoggerConfig(
batch_size=1,
batch_flush_interval=0.5,
log_session_metadata=True,
),
)
# --- 工具 ---
credentials, _ = google.auth.default(
scopes=["https://www.googleapis.com/auth/cloud-platform"]
)
bigquery_toolset = BigQueryToolset(
credentials_config=BigQueryCredentialsConfig(credentials=credentials)
)
# --- 智能体 ---
root_agent = Agent(
model=Gemini(model="gemini-flash-latest"),
name="my_bq_agent",
instruction="你是一个可以访问 BigQuery 工具的得力助手。",
tools=[bigquery_toolset],
)
# --- App (required for Agent Runtime with plugins) ---
app = App(
name="my_bq_agent",
root_agent=root_agent,
plugins=[bq_analytics_plugin],
)
google-adk[bigquery]
google-cloud-bigquery-storage
pyarrow
opentelemetry-api
opentelemetry-sdk
步骤 2:使用 ADK CLI 部署¶
使用 adk deploy agent_engine 命令部署智能体。--adk_app 标志告诉 CLI 使用哪个 App 对象:
PROJECT_ID=your-gcp-project-id
LOCATION=us-central1
adk deploy agent_engine \
--project=$PROJECT_ID \
--region=$LOCATION \
--staging_bucket=gs://your-staging-bucket \
--display_name="My BQ Analytics Agent" \
--adk_app=agent.app \
my_bq_agent
--adk_app 标志
--adk_app 标志指定 App 对象的模块路径和变量名(格式为 module.variable)。在此示例中,agent.app 引用 agent.py 中的 app 变量。这确保部署正确获取插件配置。
成功部署后,你应该会看到类似如下的输出:
AgentEngine created. Resource name: projects/123456789/locations/us-central1/reasoningEngines/751619551677906944
请记下 Resource name,以便进行下一步操作。
步骤 3:测试已部署的智能体¶
部署后,你可以使用 Agent Platform SDK 查询智能体:
import uuid
import vertexai
PROJECT_ID = "your-gcp-project-id"
LOCATION = "us-central1"
AGENT_ID = "751619551677906944" # 来自部署输出
vertexai.init(project=PROJECT_ID, location=LOCATION)
client = vertexai.Client(project=PROJECT_ID, location=LOCATION)
agent = client.agent_engines.get(
name=f"projects/{PROJECT_ID}/locations/{LOCATION}/reasoningEngines/{AGENT_ID}"
)
user_id = f"test_user_{uuid.uuid4().hex[:8]}"
for chunk in agent.stream_query(
message="列出我的项目中的数据集", user_id=user_id
):
print(chunk, end="", flush=True)
步骤 4:在 BigQuery 中验证事件¶
向已部署的智能体发送几次查询后,通过查询 BigQuery 表来验证事件是否正在被记录:
SELECT timestamp, event_type, agent, content
FROM `your-gcp-project-id.agent_analytics.agent_events`
ORDER BY timestamp DESC
LIMIT 20;
你应该会看到诸如 INVOCATION_STARTING、LLM_REQUEST、LLM_RESPONSE、TOOL_STARTING、TOOL_COMPLETED 和 INVOCATION_COMPLETED 等事件。
替代方案:使用 Agent Platform SDK 部署¶
你也可以直接使用 Agent Platform SDK 以编程方式部署。这对于 CI/CD 流水线或自定义部署工作流非常有用:
import vertexai
from my_bq_agent.agent import app
PROJECT_ID = "your-gcp-project-id"
LOCATION = "us-central1"
STAGING_BUCKET = "gs://your-staging-bucket"
vertexai.init(
project=PROJECT_ID, location=LOCATION, staging_bucket=STAGING_BUCKET
)
client = vertexai.Client(project=PROJECT_ID, location=LOCATION)
remote_app = client.agent_engines.create(
agent=app,
config={
"display_name": "My BQ Analytics Agent",
"staging_bucket": STAGING_BUCKET,
"requirements": [
"google-adk[bigquery]",
"google-cloud-aiplatform[agent_engines]",
"google-cloud-bigquery-storage",
"pyarrow",
"opentelemetry-api",
"opentelemetry-sdk",
],
},
)
print(f"Deployed agent: {remote_app.api_resource.name}")
故障排查¶
如果部署后事件未出现在你的 BigQuery 表中:
-
检查 ADK 版本:确保
google-adk>=1.24.0在你的依赖中。早期版本在无服务器运行时挂起进程之前不会刷新待处理事件。 -
启用调试日志:在
agent.py顶部添加以下内容以显示任何静默错误: -
检查 IAM 权限:Agent Runtime 服务账号需要目标表上的
roles/bigquery.dataEditor和项目上的roles/bigquery.jobUser。对于跨项目日志记录,还需确保源项目中已启用 BigQuery API,并且服务账号对目标表具有bigquery.tables.updateData权限。 -
验证插件初始化:在 Cloud Logging 中,按
resource.type="reasoning_engine"过滤,查找插件启动消息或错误日志。 -
使用即时刷新进行调试:在
BigQueryLoggerConfig中设置batch_size=1和batch_flush_interval=0.1,以排除缓冲问题。
安全性:避免记录敏感凭据¶
请勿记录 OAuth 令牌、API 密钥或客户端密钥
BigQuery 智能体分析插件会捕获详细的事件负载,包括工具参数、LLM 提示和身份验证相关事件(例如 HITL 凭据请求)。如果你的智能体使用已认证的工具(例如带有 OAuth2 的 AuthenticatedFunctionTool),插件可能会将敏感值(例如 client_secret、access_token 或 API 密钥)记录到 BigQuery 表的 content 列中。
这是一个已知问题(google/adk-python#3845),并可能导致你的分析数据中发生凭据泄露。
插件包含内置脱敏功能,可自动保护常见的密钥。如需额外控制,你可以在其之上叠加自定义脱敏。
内置脱敏¶
插件会自动脱敏以下众所周知的键名(不区分大小写),无论它们出现在 content 或 attributes JSON 中的哪个位置:
client_secret、access_token、refresh_token、id_token、api_key、
password
此外,任何以 temp: 或 secret: 为前缀的状态键在记录的 state_delta 中都会自动替换为 [REDACTED]。这意味着 ADK 会话状态下 secret: 范围存储的内容(例如凭据服务缓存的 OAuth 令牌)永远不会持久化到 BigQuery 中。
内置脱敏始终对结构化属性和状态日志记录生效,并递归应用于嵌套字典和属性值中的 JSON 编码字符串。自定义 content_formatter 在原始内容上首先运行,因此使用它来为可能出现在自由格式负载中的密钥添加掩码。
使用 content_formatter 脱敏其他密钥¶
在 BigQueryLoggerConfig 中提供自定义的 content_formatter 函数,以便在写入之前剥离或掩码敏感字段:
```python
import json
import re
from typing import Any
SENSITIVE_KEYS = {"client_secret", "access_token", "refresh_token", "api_key", "secret"}
def redact_credentials(event_content: Any, event_type: str) -> str:
"""Redact OAuth secrets and tokens from logged content."""
if isinstance(event_content, dict):
text = json.dumps(event_content)
else:
text = str(event_content)
for key in SENSITIVE_KEYS:
# Redact values in JSON-like strings: "client_secret": "GOCSPX-xxx"
text = re.sub(
rf'("{key}"\s*:\s*)"[^"]*"',
rf'\1"[REDACTED]"',
text,
flags=re.IGNORECASE,
)
return text
config = BigQueryLoggerConfig(
content_formatter=redact_credentials,
# ... other options
)
```
import com.google.adk.plugins.agentanalytics.BigQueryLoggerConfig;
import java.util.function.BiFunction;
import java.util.Set;
Set<String> SENSITIVE_KEYS = Set.of("client_secret", "access_token", "refresh_token", "api_key", "secret");
BiFunction<Object, String, Object> redactCredentials = (content, eventType) -> {
String text = content.toString();
for (String key : SENSITIVE_KEYS) {
// Redact values in JSON-like strings: "client_secret": "GOCSPX-xxx"
text = text.replaceAll(
"(?i)(\"" + key + "\"\\s*:\\s*)\"[^\"]*\"",
"$1\"[REDACTED]\""
);
}
return text;
};
BigQueryLoggerConfig config = BigQueryLoggerConfig.builder()
.contentFormatter(redactCredentials)
// ... other options
.build();
使用 event_denylist 跳过凭据事件¶
如果你不需要记录身份验证相关的事件,可以将其完全排除:
通用最佳实践¶
- 永远不要在智能体源代码中硬编码密钥。使用环境变量或密钥管理服务(例如 Google Cloud Secret Manager)来管理 OAuth 客户端密钥和 API 密钥。
- 使用 IAM 限制 BigQuery 表访问权限,以限制谁可以读取记录的事件数据。
- 定期审计你的日志,确保没有意外的敏感数据被捕获。
操作¶
追踪与可观测性¶
插件支持 OpenTelemetry 进行分布式追踪。OpenTelemetry 作为 ADK 的核心依赖包含在内,始终可用。
- 自动 Span 管理:插件会自动为智能体执行、LLM 调用和工具执行生成 spans。
- OpenTelemetry 集成:如果配置了
TracerProvider(如上例所示),插件将使用有效的 OTel spans,用标准的 OTel 标识符填充trace_id、span_id和parent_span_id。这使你能够将智能体日志与分布式系统中的其他服务关联起来。 - 回退机制:如果没有配置
TracerProvider(即仅激活了默认的 no-op 提供者),插件会自动回退到为 spans 生成内部 UUID,并使用invocation_id作为 trace ID。这确保了父子层级关系(智能体 -> Span -> 工具/LLM)在 BigQuery 日志中始终得到保留,即使没有配置TracerProvider。
公共方法¶
The plugin exposes several public methods for lifecycle management:
await plugin.flush(): Flush all pending events to BigQuery. Call this before shutdown to avoid data loss.await plugin.shutdown(timeout=None): Gracefully shut down the plugin, flushing pending events and releasing resources. The optionaltimeoutparameter overridesshutdown_timeoutfrom the config.await plugin.create_analytics_views(): Manually (re-)create all per-event-type analytics views. Useful after a schema upgrade or when views need to be refreshed.-
Async context manager: The plugin supports
async withfor automatic startup and shutdown:
In Java, the plugin lifecycle is managed via the close() method (inherited from Plugin), which returns an RxJava Completable.
plugin.close(): Gracefully shuts down the plugin, flushing pending events and releasing resources (including the BigQuery write client and executors).- Automatic Closure: If you are using
InMemoryRunner, callingrunner.close()will automatically close all registered plugins, including the BigQuery Agent Analytics plugin.
多进程与 fork 安全¶
插件具有 fork 感知能力:它在加载 gRPC C-core 库之前设置 GRPC_ENABLE_FORK_SUPPORT=1,并注册一个 os.register_at_fork 处理程序,在子进程中重置继承的运行时状态(gRPC 通道、写入流、事件循环)。这意味着插件可以在不泄漏文件描述符或在父连接上发送数据的情况下承受 os.fork()。
但是,对于生产部署,spawn 是推荐的多进程启动方法。fork 会复制父进程的地址空间,包括任何正在进行的 gRPC 状态,而 fork 后的重置会增加每个子进程首次写入的延迟。使用 spawn,每个工作进程都会干净地初始化插件。
对于 Gunicorn 部署:
- 优先使用
--preload配合惰性插件初始化(插件会延迟设置直到第一个事件被记录),或者 - 在
post_fork钩子中初始化插件,以便每个工作进程获得自己的客户端。
Note
Fork 安全机制仅重置运行时状态。它不会重放在 fork 时已在父进程中排队但尚未刷新的事件。如果需要保证交付,请在 fork 前调用 await plugin.flush()。
消费记录数据的其他方式¶
BigQuery 智能体分析 SDK¶
BigQuery 智能体分析 SDK 提供了一种以编程方式消费和分析插件记录的数据的方式。使用 SDK 进行:
- 智能体评估:将智能体运行结果与预期结果进行对比
- 黄金轨迹匹配:验证智能体执行路径是否与批准的序列匹配
- 追踪可视化:从记录的 spans 重建和可视化智能体执行流
构建仪表板¶
BigQuery 智能体分析 SDK 包含一个示例 Jupyter notebook,演示了如何查询和可视化智能体的性能数据。将其作为构建自定义仪表板的起点,以适应你的 BigQuery 智能体分析数据集。你还可以使用 Colab Data Apps 将 notebook 发布为交互式仪表板。
反馈¶
我们欢迎你对 BigQuery 智能体分析插件提供反馈。如果你有任何疑问、建议或遇到任何问题,请通过 bqaa-feedback@google.com 联系团队。